> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Custom Code-Based Metrics
> Learn how to create, register, and use custom code-based metrics to evaluate your LLM applications
Custom metrics allow you to define specific evaluation criteria for your LLM applications. Galileo supports two types of custom metrics:
* **Registered custom metrics**: Metrics that can be shared across your organization
* **Local metrics**: Metrics that run in your local notebook environment
## Registered custom metrics
Registered custom metrics are stored and run in Galileo's environment and can be used across your organization.
### Create a registered custom metric
You can create a registered custom metric either through the Python SDK or directly in the Galileo UI. Let's walk through the UI approach:
In the Galileo platform, go to the Metrics section and select the **Create New Metric** button in the top right corner.
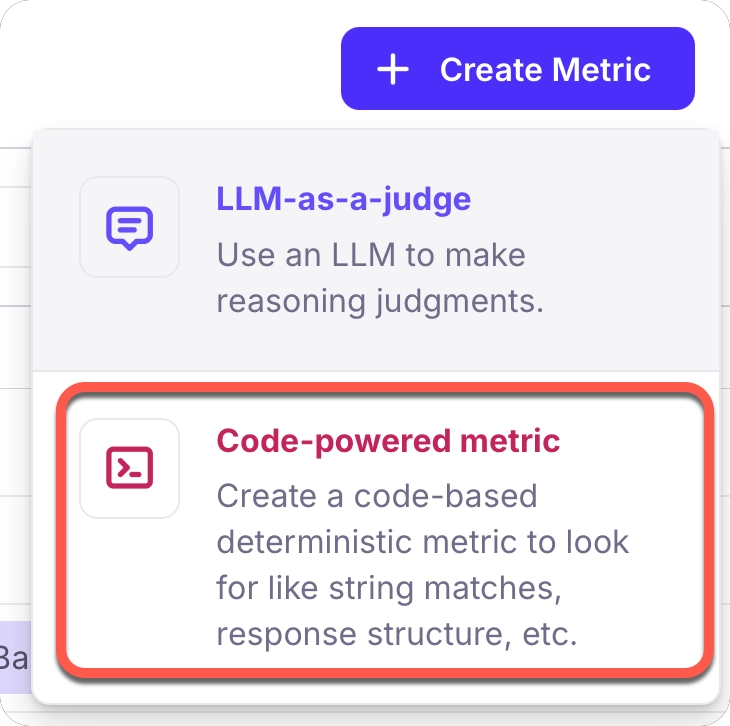
 From the dialog that appears, choose the **Code-powered metric** type. This option allows you to write custom Python code to evaluate your LLM outputs.
From the dialog that appears, choose the **Code-powered metric** type. This option allows you to write custom Python code to evaluate your LLM outputs.
 Select the step level you'd like to apply this metric to (ie: Sessions, Traces, LlmSpan, etc...). Then, use the code editor to write your custom metric. The editor provides a template with the required functions and helpful comments to guide you.
Select the step level you'd like to apply this metric to (ie: Sessions, Traces, LlmSpan, etc...). Then, use the code editor to write your custom metric. The editor provides a template with the required functions and helpful comments to guide you.
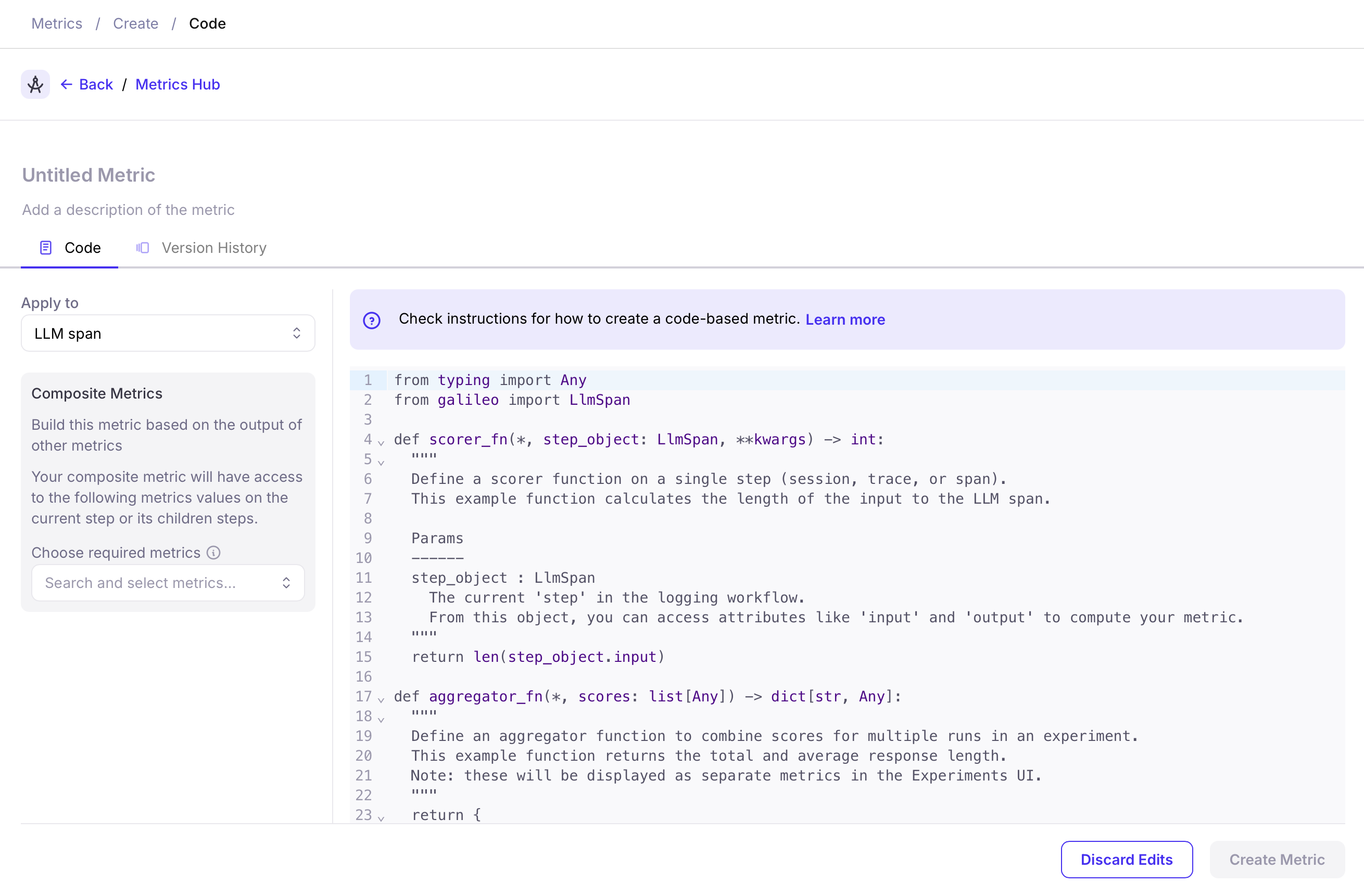 The code editor allows you to write and test your metric directly in the browser. You'll need to define the `scorer_fn` function as described below.
After writing your custom metric code, select the **Save** button in the bottom right corner of the code editor. Your metric will be validated and, if there are no errors, it will be saved and become available for use across your organization.
You can now select this metric when running evaluations.
#### The scorer function
This function evaluates individual responses and returns a score:
```python Python theme={null}
def scorer_fn(
*,
step_object: (
Session | Trace | WorkflowSpan | AgentSpan |
LlmSpan | RetrieverSpan | ToolSpan
),
**kwargs: Any
) -> float | int | bool | str:
# Your scoring logic here
return score
```
The function must accept `**kwargs` to ensure forward/backward compatibility. Here's a complete example that measures the difference in length between the output and ground truth:
```python Python theme={null}
def scorer_fn(*,
step_object: LlmSpan,
**kwargs: Any) -> Union[float, int, bool, str, None]:
step_output = step_object.output.content
reference_output = step_object.dataset_output
return abs(len(step_output) - len(reference_output))
```
**Parameter details:**
* **`step_object`**: The step object represents the unit of your LLM application being evaluated. It can be one of several types from the `galileo` library:
* `Session` - A complete user session containing multiple traces
* `Trace` - A single execution trace containing multiple spans
* `WorkflowSpan` - A workflow-level span containing child spans
* `AgentSpan` - An agent execution span
* `LlmSpan` - A single LLM call span
* `RetrieverSpan` - A retriever/search operation span
* `ToolSpan` - A tool execution span
All step objects provide access to key attributes for evaluation:
* **Input/Output data**: Access the input prompt and generated output (e.g., `step_object.output.content` for LLM responses)
* **Metadata**: Additional context like timestamps, model information, and custom metadata
* **Dataset references**: Ground truth or reference data when available (e.g., `step_object.dataset_output`)
* **Hierarchical data**: For Session/Trace/Workflow objects, access child spans and nested execution data
For detailed documentation on each step object type and their specific attributes, refer to the [Galileo Python SDK documentation](/sdk-api/python/sdk-reference). Each type has unique properties tailored to its execution context—for example, `LlmSpan` includes model parameters and token counts, while `RetrieverSpan` includes retrieved documents and search queries.
### Complete example: trace counter
Let's create a custom metric that counts the number of traces in a Session:
```python Python theme={null}
from galileo import Session
def scorer_fn(*, step_object: Session, **kwargs) -> int:
num_traces = len(step_object.traces)
return num_traces
```
### Creating composite metrics
Composite metrics are advanced custom metrics that can access and leverage the
results of other metrics to perform sophisticated evaluations. This allows you
to create conditional logic, aggregate multiple metrics, or build hierarchical
evaluations.
To create a composite metric in the UI:
1. When creating a code-based custom metric, use the **Composite Metrics**
dropdown to select which metrics must be computed before your composite
metric runs
The code editor allows you to write and test your metric directly in the browser. You'll need to define the `scorer_fn` function as described below.
After writing your custom metric code, select the **Save** button in the bottom right corner of the code editor. Your metric will be validated and, if there are no errors, it will be saved and become available for use across your organization.
You can now select this metric when running evaluations.
#### The scorer function
This function evaluates individual responses and returns a score:
```python Python theme={null}
def scorer_fn(
*,
step_object: (
Session | Trace | WorkflowSpan | AgentSpan |
LlmSpan | RetrieverSpan | ToolSpan
),
**kwargs: Any
) -> float | int | bool | str:
# Your scoring logic here
return score
```
The function must accept `**kwargs` to ensure forward/backward compatibility. Here's a complete example that measures the difference in length between the output and ground truth:
```python Python theme={null}
def scorer_fn(*,
step_object: LlmSpan,
**kwargs: Any) -> Union[float, int, bool, str, None]:
step_output = step_object.output.content
reference_output = step_object.dataset_output
return abs(len(step_output) - len(reference_output))
```
**Parameter details:**
* **`step_object`**: The step object represents the unit of your LLM application being evaluated. It can be one of several types from the `galileo` library:
* `Session` - A complete user session containing multiple traces
* `Trace` - A single execution trace containing multiple spans
* `WorkflowSpan` - A workflow-level span containing child spans
* `AgentSpan` - An agent execution span
* `LlmSpan` - A single LLM call span
* `RetrieverSpan` - A retriever/search operation span
* `ToolSpan` - A tool execution span
All step objects provide access to key attributes for evaluation:
* **Input/Output data**: Access the input prompt and generated output (e.g., `step_object.output.content` for LLM responses)
* **Metadata**: Additional context like timestamps, model information, and custom metadata
* **Dataset references**: Ground truth or reference data when available (e.g., `step_object.dataset_output`)
* **Hierarchical data**: For Session/Trace/Workflow objects, access child spans and nested execution data
For detailed documentation on each step object type and their specific attributes, refer to the [Galileo Python SDK documentation](/sdk-api/python/sdk-reference). Each type has unique properties tailored to its execution context—for example, `LlmSpan` includes model parameters and token counts, while `RetrieverSpan` includes retrieved documents and search queries.
### Complete example: trace counter
Let's create a custom metric that counts the number of traces in a Session:
```python Python theme={null}
from galileo import Session
def scorer_fn(*, step_object: Session, **kwargs) -> int:
num_traces = len(step_object.traces)
return num_traces
```
### Creating composite metrics
Composite metrics are advanced custom metrics that can access and leverage the
results of other metrics to perform sophisticated evaluations. This allows you
to create conditional logic, aggregate multiple metrics, or build hierarchical
evaluations.
To create a composite metric in the UI:
1. When creating a code-based custom metric, use the **Composite Metrics**
dropdown to select which metrics must be computed before your composite
metric runs
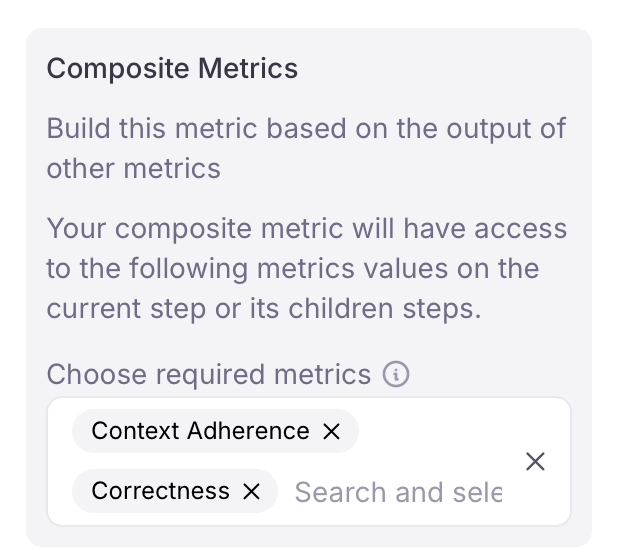 2. Access the required metric values in your scorer function via
`step_object.metrics`
#### Example: Conditional evaluation based on other metrics
```python Python theme={null}
from statistics import mean
from galileo import GalileoMetrics, LlmSpan
def scorer_fn(*, step_object: LlmSpan, **kwargs) -> float:
# Access required metrics via step_object.metrics
# These metrics were selected in the "Required Metrics" dropdown
# Multi-judge metrics (e.g. correctness, context_adherence) return
# a list of 0/1 values, one per judge. Use mean() to get the score.
correctness_score = mean(
step_object.metrics[GalileoMetrics.correctness] or [0]
)
if correctness_score < 0.7:
return 0.0
return mean(
step_object.metrics[GalileoMetrics.context_adherence] or [0]
)
```
#### Referencing metrics
* **Galileo preset metrics**: Use the `GalileoMetrics` enum (e.g.,
`GalileoMetrics.context_adherence`)
* **Custom metrics**: Use the metric name as a string (e.g.,
`step_object.metrics["My Custom Metric"]`)
Composite metrics are **only supported for code-based custom metrics**.
For a comprehensive guide including use cases and best practices, see the
[Composite Metrics](/concepts/metrics/custom-metrics/composite-metrics)
documentation.
### Execution environment
Registered custom metrics run in a sandbox Python 3.10 environment with only
the Python standard library and the Galileo SDK installed.
To install your own PyPI package, you can define dependencies at the top of the
file using the script dependency format from `uv`:
```toml uv theme={null}
# /// script
# dependencies = [
# "requests<3",
# "rich",
# ]
# ///
```
For full documentation on defining dependencies, check out the
['uv' script dependency docs](https://docs.astral.sh/uv/guides/scripts/#creating-a-python-script).
## Local metrics
A **Local metric** (or *Local scorer*) is a custom metric that you can attach to an experiment — just like a Galileo preset metric. The key difference is that a Local Metric lives in code on your machine, so you share it by sharing your code. Local Metrics are ideal for running isolated tests and refining outcomes when you need more control than built-in metrics offer.
You can also use any library or custom Python code with your local metrics, including calling out to LLMs or other APIs.
Galileo currently only supports Local scorers in Python
### Local scorer components
A Local scorer consists of three main parts:
1. **Scorer Function**
Receives a single [`Span`](/sdk-api/logging/galileo-logger#add-spans) or [`Trace`](/sdk-api/logging/galileo-logger#start-a-trace) containing the LLM input and output, and computes a score. The exact measurement is up to you — for example, you might measure the length of the output or rate it based on the presence/absence of specific words.
2. **`LocalMetricConfig[type]`**
A typed callable provided by Galileo's Python SDK that combines your Scorer into a custom metric.
* **Example:** If your Scorer returns `bool` values, you would use `LocalMetricConfig[bool](…)`.
Scorer function can be a simple lambda when your logic is straightforward.
Local metrics let you tailor evaluation to your exact needs by defining custom scoring logic in code. Whether you want to measure response brevity, detect specific keywords, or implement a complex scoring algorithm, Local Metrics integrate seamlessly with Galileo's experimentation framework. Once you've defined your **Scorer** function and wrapped it in a `LocalMetricConfig`, running the experiment is as simple as calling `run_experiment`. The results appear alongside Galileo's built-in metrics, so you can compare, visualize, and analyze everything in one place.
With local metrics, you have full control over how you measure LLM behavior—unlocking deeper insights and more targeted evaluations for your AI applications.
Learn how to create a local metric in Python to use in your experiments
### Comparison: registered custom metrics vs. local metrics
| Feature | Registered Custom Metrics | Local Metrics |
| :-------------- | :------------------------------ | :----------------------- |
| **Creation** | Python client, activated via UI | Python client only |
| **Sharing** | Organization-wide | Current project only |
| **Environment** | Server-side | Local Python environment |
| **Libraries** | Any available library. | Any available library |
| **Resources** | Restricted by Galileo | Local resources |
### Common use cases
Custom metrics are ideal for:
* **Heuristic evaluation**: Checking for specific patterns, keywords, or structural elements
* **Model-guided evaluation**: Using pre-trained models to detect entities or LLMs to grade outputs
* **Business-specific metrics**: Measuring domain-specific quality indicators
* **Comparative analysis**: Comparing outputs against ground truth or reference data
### Simple example: sentiment scorer
Here's a simple custom metric that evaluates the sentiment of responses:
```python Python theme={null}
from galileo import Span, Trace
def scorer_fn(step: Span | Trace) -> float:
"""
A simple sentiment scorer that counts positive and negative words.
Returns a score between -1 (negative) and 1 (positive).
"""
positive_words = [
"good", "great", "excellent",
"positive", "happy", "best", "wonderful"
]
negative_words = [
"bad", "poor", "negative", "terrible",
"worst", "awful", "horrible"
]
step_output = step.output.content
# Convert to lowercase for case-insensitive matching
text = step_output.lower()
# Count occurrences
positive_count = sum(text.count(word) for word in positive_words)
negative_count = sum(text.count(word) for word in negative_words)
total_count = positive_count + negative_count
# Calculate sentiment score
if total_count == 0:
return 0.0 # Neutral
return (positive_count - negative_count) / total_count
```
This simple sentiment scorer:
* Counts positive and negative words in responses
* Calculates a sentiment score between -1 (negative) and 1 (positive)
* Aggregates results to show the distribution of positive, neutral, and negative responses
You can easily extend this with more sophisticated sentiment analysis techniques or domain-specific terminology.
## Next steps
Learn how to create custom LLM-as-a-judge metrics in the Galileo console or in code.
Learn best practices for prompt engineering with custom LLM-as-a-judge metrics.
Explore Galileo's comprehensive metrics framework for evaluating and improving AI system performance across multiple dimensions.
Learn how to create a local metric in Python to use in your experiments
Learn how to run experiments in Galileo using the Galileo SDKs and custom metrics.
2. Access the required metric values in your scorer function via
`step_object.metrics`
#### Example: Conditional evaluation based on other metrics
```python Python theme={null}
from statistics import mean
from galileo import GalileoMetrics, LlmSpan
def scorer_fn(*, step_object: LlmSpan, **kwargs) -> float:
# Access required metrics via step_object.metrics
# These metrics were selected in the "Required Metrics" dropdown
# Multi-judge metrics (e.g. correctness, context_adherence) return
# a list of 0/1 values, one per judge. Use mean() to get the score.
correctness_score = mean(
step_object.metrics[GalileoMetrics.correctness] or [0]
)
if correctness_score < 0.7:
return 0.0
return mean(
step_object.metrics[GalileoMetrics.context_adherence] or [0]
)
```
#### Referencing metrics
* **Galileo preset metrics**: Use the `GalileoMetrics` enum (e.g.,
`GalileoMetrics.context_adherence`)
* **Custom metrics**: Use the metric name as a string (e.g.,
`step_object.metrics["My Custom Metric"]`)
Composite metrics are **only supported for code-based custom metrics**.
For a comprehensive guide including use cases and best practices, see the
[Composite Metrics](/concepts/metrics/custom-metrics/composite-metrics)
documentation.
### Execution environment
Registered custom metrics run in a sandbox Python 3.10 environment with only
the Python standard library and the Galileo SDK installed.
To install your own PyPI package, you can define dependencies at the top of the
file using the script dependency format from `uv`:
```toml uv theme={null}
# /// script
# dependencies = [
# "requests<3",
# "rich",
# ]
# ///
```
For full documentation on defining dependencies, check out the
['uv' script dependency docs](https://docs.astral.sh/uv/guides/scripts/#creating-a-python-script).
## Local metrics
A **Local metric** (or *Local scorer*) is a custom metric that you can attach to an experiment — just like a Galileo preset metric. The key difference is that a Local Metric lives in code on your machine, so you share it by sharing your code. Local Metrics are ideal for running isolated tests and refining outcomes when you need more control than built-in metrics offer.
You can also use any library or custom Python code with your local metrics, including calling out to LLMs or other APIs.
Galileo currently only supports Local scorers in Python
### Local scorer components
A Local scorer consists of three main parts:
1. **Scorer Function**
Receives a single [`Span`](/sdk-api/logging/galileo-logger#add-spans) or [`Trace`](/sdk-api/logging/galileo-logger#start-a-trace) containing the LLM input and output, and computes a score. The exact measurement is up to you — for example, you might measure the length of the output or rate it based on the presence/absence of specific words.
2. **`LocalMetricConfig[type]`**
A typed callable provided by Galileo's Python SDK that combines your Scorer into a custom metric.
* **Example:** If your Scorer returns `bool` values, you would use `LocalMetricConfig[bool](…)`.
Scorer function can be a simple lambda when your logic is straightforward.
Local metrics let you tailor evaluation to your exact needs by defining custom scoring logic in code. Whether you want to measure response brevity, detect specific keywords, or implement a complex scoring algorithm, Local Metrics integrate seamlessly with Galileo's experimentation framework. Once you've defined your **Scorer** function and wrapped it in a `LocalMetricConfig`, running the experiment is as simple as calling `run_experiment`. The results appear alongside Galileo's built-in metrics, so you can compare, visualize, and analyze everything in one place.
With local metrics, you have full control over how you measure LLM behavior—unlocking deeper insights and more targeted evaluations for your AI applications.
Learn how to create a local metric in Python to use in your experiments
### Comparison: registered custom metrics vs. local metrics
| Feature | Registered Custom Metrics | Local Metrics |
| :-------------- | :------------------------------ | :----------------------- |
| **Creation** | Python client, activated via UI | Python client only |
| **Sharing** | Organization-wide | Current project only |
| **Environment** | Server-side | Local Python environment |
| **Libraries** | Any available library. | Any available library |
| **Resources** | Restricted by Galileo | Local resources |
### Common use cases
Custom metrics are ideal for:
* **Heuristic evaluation**: Checking for specific patterns, keywords, or structural elements
* **Model-guided evaluation**: Using pre-trained models to detect entities or LLMs to grade outputs
* **Business-specific metrics**: Measuring domain-specific quality indicators
* **Comparative analysis**: Comparing outputs against ground truth or reference data
### Simple example: sentiment scorer
Here's a simple custom metric that evaluates the sentiment of responses:
```python Python theme={null}
from galileo import Span, Trace
def scorer_fn(step: Span | Trace) -> float:
"""
A simple sentiment scorer that counts positive and negative words.
Returns a score between -1 (negative) and 1 (positive).
"""
positive_words = [
"good", "great", "excellent",
"positive", "happy", "best", "wonderful"
]
negative_words = [
"bad", "poor", "negative", "terrible",
"worst", "awful", "horrible"
]
step_output = step.output.content
# Convert to lowercase for case-insensitive matching
text = step_output.lower()
# Count occurrences
positive_count = sum(text.count(word) for word in positive_words)
negative_count = sum(text.count(word) for word in negative_words)
total_count = positive_count + negative_count
# Calculate sentiment score
if total_count == 0:
return 0.0 # Neutral
return (positive_count - negative_count) / total_count
```
This simple sentiment scorer:
* Counts positive and negative words in responses
* Calculates a sentiment score between -1 (negative) and 1 (positive)
* Aggregates results to show the distribution of positive, neutral, and negative responses
You can easily extend this with more sophisticated sentiment analysis techniques or domain-specific terminology.
## Next steps
Learn how to create custom LLM-as-a-judge metrics in the Galileo console or in code.
Learn best practices for prompt engineering with custom LLM-as-a-judge metrics.
Explore Galileo's comprehensive metrics framework for evaluating and improving AI system performance across multiple dimensions.
Learn how to create a local metric in Python to use in your experiments
Learn how to run experiments in Galileo using the Galileo SDKs and custom metrics.