Setup: Install Libraries
Construct Dataset and Embed Documents
For our RAG application, we will have the following pieces.- Dataset: Galileo blog post
- Chunking: LangChain RecursiveCharacterTextSplitter
- Embeddings: text-embedding-ada-002
- Vector Store: ChromaDB in-memory
- Retriever: Chroma document retriever with k=3 docs
Define the Pieces of Our Chain
Now we have the retriever, we can build our chain. The chain will:- Take in a question.
- Feed that question to our retriever for some context based on distance in embedding space.
- Fill out the prompt template with the question and context.
- Feed the prompt to our chat model.
- Output and parse the answer from the model.
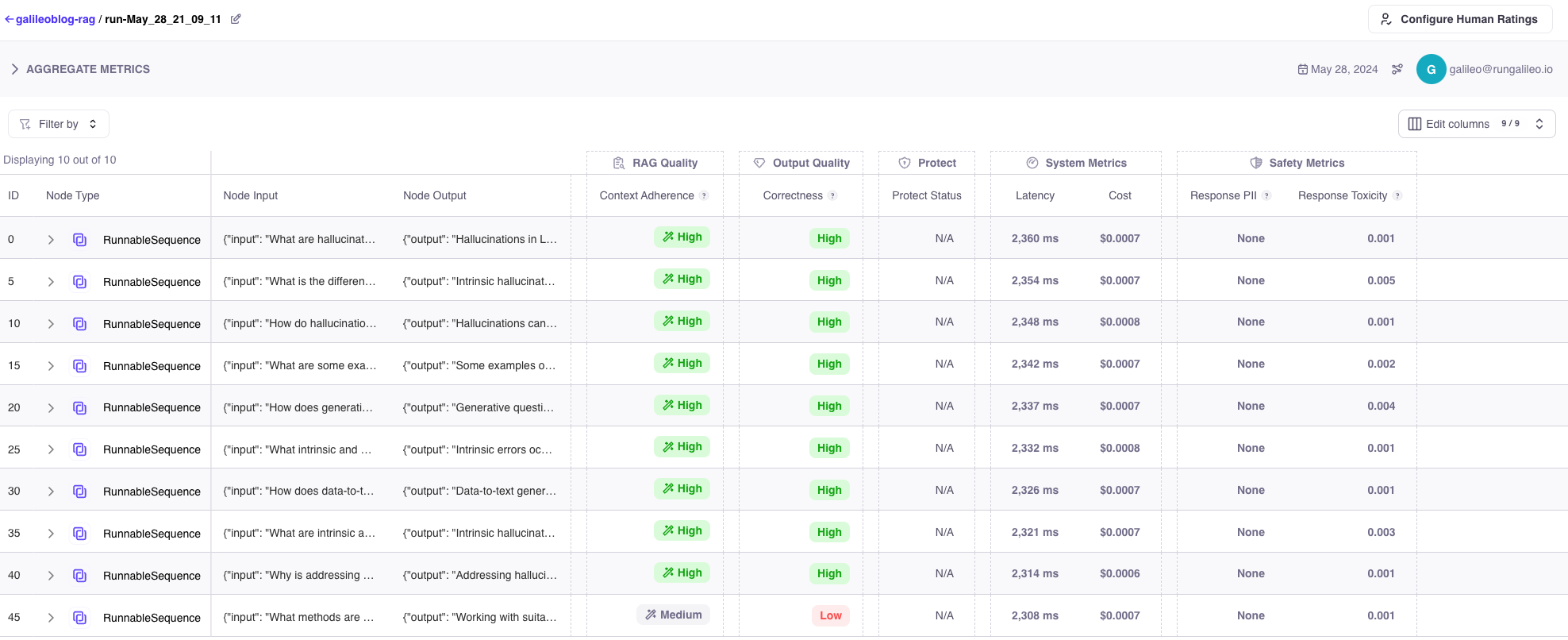
Run Our Chain and Submit Callback to Galileo
Next, we will set our Galileo cluster url, API key, and project name in order to define where we want to log our results. Finally, we can run our chain and configure a callback to theGalileoPromptCallback to log our results.