Setup: Install Library and Set Up Variables
We will usepromptquality, the Python client to interact with Galileo’s GenAI Studio: Evaluate.
Construct Dataset: Subsample of HotpotQA
We will be using (a subsample of) HotpotQA, a public Q&A dataset with question, context, and ground truths aliases. HotpotQA has easy, medium, and hard tasks that are challenging even for the most modern LLM releases. In lieu of evaluating model responses against the ground truths, we can leverage Galileo’s metrics to gauge hallucinations.Define our Classification Pipeline
We will use a checkpoint for bart-large that has been trained on the MultiNLI (MNLI) dataset, which is a dataset of sentence pairs annotated with textual entailment information. This makes it ideal as an off-the-shelf zero-shot topic classification model.Implementing our Pipeline as a Galileo CustomMetric
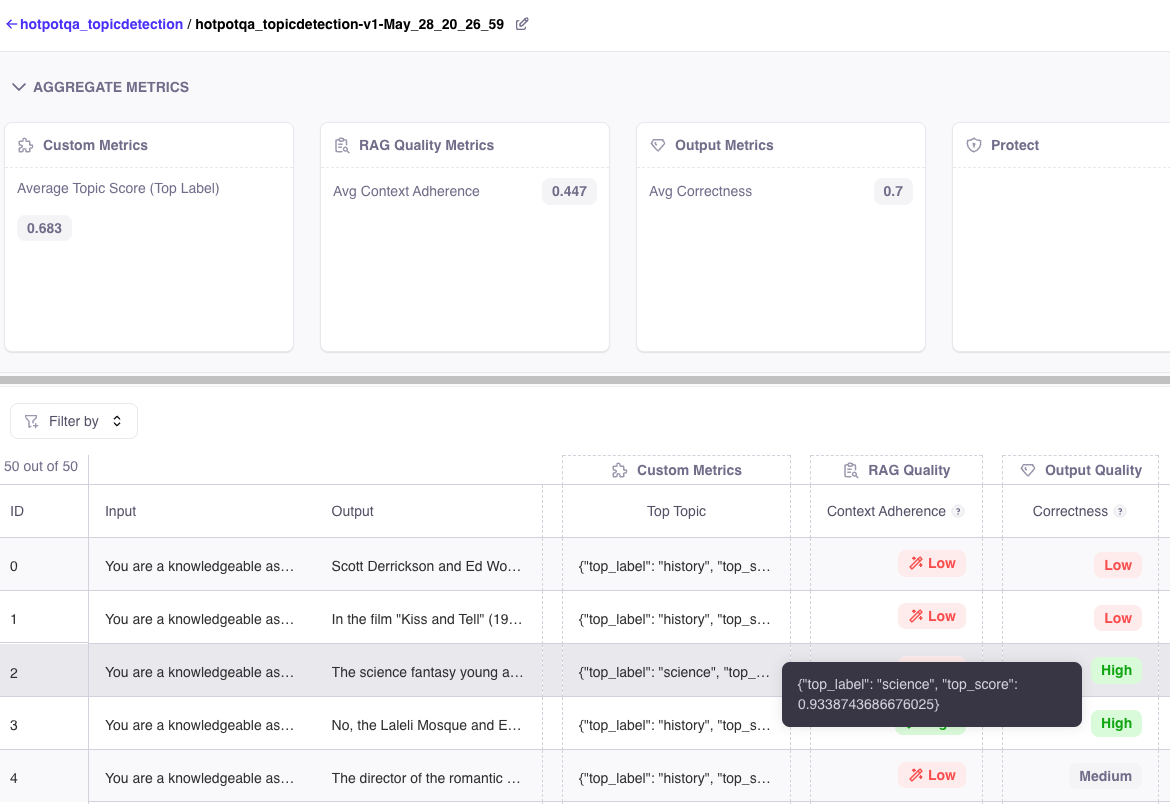
We will define a small space of candidate labels for this zero-shot topic detection task. We also define anexecutor and aggregator function. The executor is a row-level calculator, while the aggregator consolidates all of the calculated row values.
In this example, I want to publish both the top topic and its score, so my executor will serialize the JSON into a string. Then, my aggregator will evaluate that string to parse the numeric label score for aggregation.
When we invoke our run, the executor and aggregator will be computed within your Python runtime / notebook / application.
Galileo Evaluate
Finally, we will define the metrics we are interested in (Galileo’s metrics) as well as our CustomMetric (Galileo’s CustomScorer class that take ourexecutor and aggregator as inputs).
We will also define our prompt template with placeholders {context} and {question}. These will be replaced by values with the same keys in our dataset.