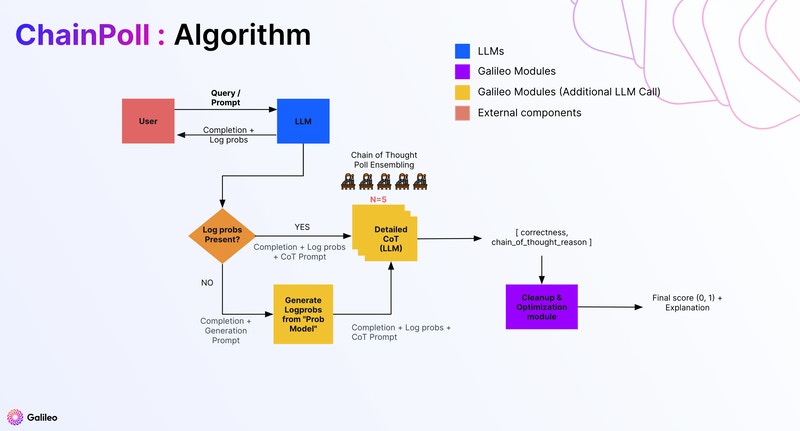
ChainPoll = Chain + Poll
ChainPoll involves two core ideas, which make up the two parts of its name:- Chain: Chain-of-thought prompting
- Poll: Prompting an LLM multiple times
Chain
Chain-of-thought prompting (CoT) is a simple but powerful way to elicit better answers from a large language model (LLM). A chain-of-thought prompt is simply a prompt that asks the LLM to write out its step-by-step reasoning process before stating its final answer. For example:-
Prompt without CoT:
- “Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?”
-
Prompt with CoT:
- “Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? Think step by step, and present your reasoning before giving the answer.”
Why does CoT Work?
To better understand why CoT works, consider that the same trick also works for human beings! If someone asks you a complex question, you will likely find it hard to answer immediately, on the spot. You’ll want some time to think about it — which could mean thinking silently, or talking through the problem out loud. Asking an LLM for an answer without using CoT is like asking a human to answer a question immediately, on the spot, without pausing to think. This might work if the human has memorized the answer, or if the question is very straightforward. For complex or difficult questions, it’s useful to take some time to reflect before answers, and CoT allows the LLM to do this.Poll
ChainPoll extends CoT prompting by soliciting multiple, independently generated responses to the same prompt, and aggregating these responses. Here’s why this is a good idea. As we all know, LLMs sometimes make mistakes. And these mistakes can occur randomly, rather than deterministically. If you ask an LLM the same question twice, you will often get two contradictory answers. This is equally true of the reasoning generated by LLMs when prompted with CoT. If you ask an LLM the same question multiple times, and ask it to explain its reasoning each time, you’ll often get a random mixture of valid and invalid arguments. But here’s the key observation: “a random mixture of valid and invalid arguments” is more useful than it sounds! Because:- All valid arguments end up in the same place: the right answer.
- But an invalid argument can lead anywhere.
From self-consistency to ChainPoll
Although ChainPoll is closely related to self-consistency, there are a few key differences. Let’s break them down. Self-consistency is a technique for picking a single best answer. It uses majority voting: the most common answer among the different LLM outputs is selected as the final answer of the entire procedure. By contrast, ChainPoll works by averaging over the answers produced by the LLM to produce a score. Most commonly, the individual answers are True-or-False, and so the average can be interpreted as the fraction of True answers among the total seto f answers. For example, in our Context Adherence metric, we ask an LLM whether a response was consistent with a set of documents. We might get a set of responses like this:- A chain of thought ending in the conclusion that Yes, the answer was supported
- A different chain of thought ending in the conclusion that Yes, the answer was supported
- A third chain of thought ending in the conclusion that No, the answer was not supported
Frequently asked questions
How does ChainPoll compare to the methods used by other LLM evaluation tools, like RAGAS and TruLens? We cover this in detail in the section below on The ChainPoll advantage. ChainPoll involves requesting multiple responses. Isn’t that slow and expensive? Not as much as you might think! We use batch requests to LLM APIs to generate ChainPoll responses, rather than generating the responses one-by-one. Because all requests in the batch have the same prompt, the API provider can process them more efficiently: the prompt only needs to be run through the LLM once, and the results can be shared across all of the sequences being generated. This efficiency improvement often corresponds to better latency or lower cost from the perspective of the API consumer (and ultimately, you). For instance, with the OpenAI API — our default choice for ChainPoll — a batch request for 3 responses from the same prompt will be billed for:- All the output tokens across all 3 responses
- All the input tokens in the prompt, counted only once (not 3 times)
- An overall inclination toward Yes or No, and
- A level of certainty/uncertainty.
-
A score of 0.667 means that the evaluating LLM said Yes 2/3 of the time, and No 1/3 of the time.
- In other words, its overall inclination was toward Yes, but it wasn’t totally sure.
- A score of 1.0 would indicate the same overall inclination, with higher confidence.
- As a guide for your own explorations, pointing out things in the data for you to review, or
- As a way to compare entire runs to one other in aggregate.
The ChainPoll advantage
ChainPoll is unique to Galileo. In this section, we’ll explore how it differs from the approaches used in products like RAGAS and TruLens, and what makes ChainPoll more effective.ChainPoll vs. RAGAS
RAGAS offers a Faithfulness score, which has a similar purpose to Galileo’s Context Adherence score. Both of these scores evaluate whether a response is consistent with the information in a context, such as the chunks provided by a RAG retriever*.* However, under the hood, the two scores work very differently. To compute Faithfulness, RAGAS calls an LLM in two distinct steps:-
The LLM is asked to break the response down into one or more granular statements.
- In this step, the LLM can only see the response, not the context.
-
The LLM given the statements and the context, and is asked to judge whether or not each statement is consistent with the context.
- In this step, the LLM can see the context, but not the original response. Instead, it only sees the statements that were written in step 1.
Statement breakdowns can be misleading
By breaking down the response into statements and judging the statements separately, RAGAS can ignore the way that different parts of the response are related. An LLM response is not just a disconnected list of “statements,” any more than this article is. It may make a complex claim or argument that loses its structure when broken down in this way. Consider this example, from a dataset related to Covid-19 that we use internally at Galileo. An LLM was given a set of documents describing medical studies, and askedRAGAS does not handle refusals sensibly
Second, RAGAS Faithfulness is unable to produce meaningful results when the LLM refuses to answer. In RAG, an LLM will sometimes respond with a refusal that claims it doesn’t have enough information: an answer like “I don’t know” or “Sorry, that wasn’t mentioned in the context.” Like any LLM response, these are sometimes appropriate and sometimes inappropriate:- If the requested information really wasn’t in the retrieved context, the LLM should say so, not make something up.
- On the other hand, if the information was there, the LLM should not assert that it wasn’t there.
RAGAS does not explain its answers
Although RAGAS does generate explanations internally (see the examples above), these are not surfaced to the user. Moreover, as you can see above, they are briefer and less illuminating than ChainPoll explanations. (We produced the examples above by adding callbacks to RAGAS to capture the requests it was making, and then following identifiers in the requests to link the steps together. You don’t get any of that out of the box.)ChainPoll vs. TruLens
TruLens offers a Groundedness score, which targets similar needs to Galileo Context Adherence and RAGAS Faithfulness: evaluating whether a response is consistent with a context. As we saw above with RAGAS, although these scores look similar on the surface, there are important differences in what they actually do. TruLens Groundedness works as follows:- The response is split up into sentences.
-
An LLM is given the list of sentences, along with the context. It is asked to:
- quote the part of the context (if any) that supports the sentence
- rate the “information overlap” between each sentence and the context on a 0-to-10 scale.
- The scores are mapped to a range from 0 to 1, and averaged to produce an overall score.