Metrics
Chunk-level metrics: Chunk Relevance, Chunk Attribution and Chunk Utilization
These metrics evaluate individual chunks retrieved by a RAG system, in light of the question and the response written by the system.- Chunk Relevance. For each chunk retrieved in a RAG pipeline, Chunk Relevance measures the fraction of the text in that chunk that is levant to the query.
- Chunk Utilization. For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model’s response.
- Chunk Attribution. For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model’s response.
Response-level metrics: Context Adherence and Completeness
These metrics capture different facets of RAG response quality. Both involve assessing the relationship between the response, the retrieved context, and the query that the RAG system is responding to.- Context Adherence. Measures whether your model’s response was purely based on the context provided.
- Completeness. Measures how thoroughly your model’s response covered the relevant information available in the context provided.
Luna Model
For a comprehensive look at the in-house model we built to predict RAG Quality metrics check out our research paper Luna: An Evaluation Foundation Model to Catch Language Model Hallucinations with High Accuracy and Low Cost Luna is a DeBERTa-large encoder that has been fine-tuned to predict RAG Quality metrics from input RAG context chunk(s), a user query, and an LLM response. Luna model predicts three sets of token-level probabilities:- Adherence probability on every token in the response.
- Relevance probability on every token of the context.
- Utilization probability on every token of the context.
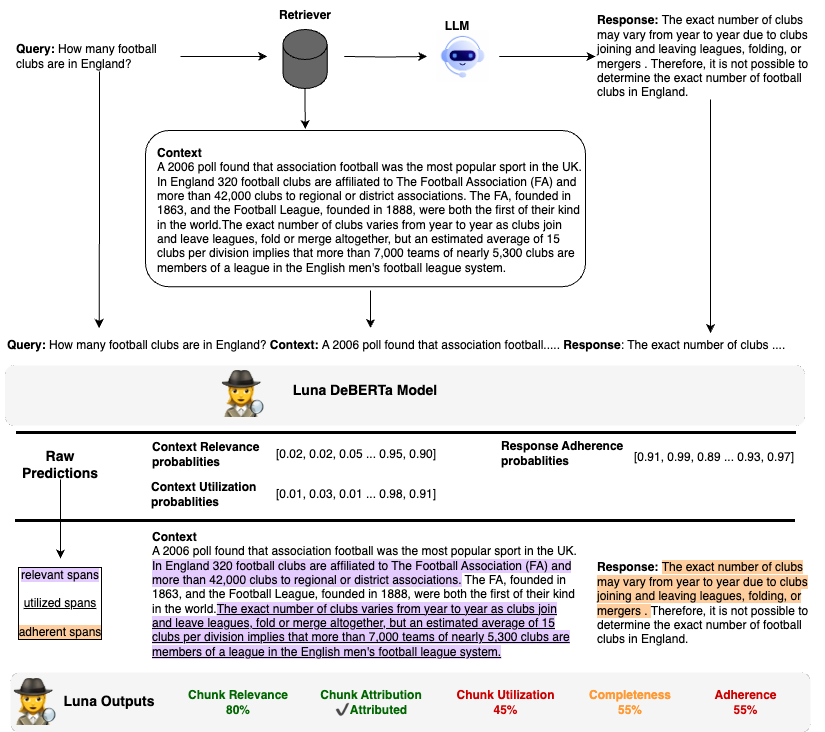
- High Chunk Relevance because the retrieved chunk is, for the most part, relevant to the input query.
- Attributed because the response uses the information in the chunk.
- Low Chunk Utilization because the response only utilizes a fraction of the information provided in the chunk.
- Low Completeness because the response utilizes ~55% of the relevant information in the retrieved chunk.
- Low Adherence because the response partially contradicts the information provided in the chunk, claiming that it is not possible to determine the numbed of football clubs in England, while the context chunk indicates otherwise.
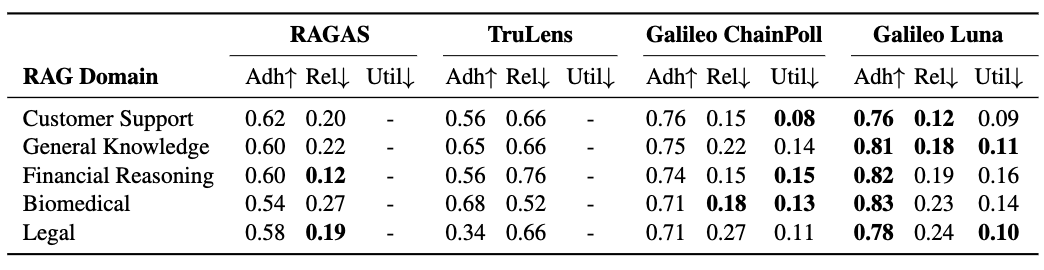
Luna Performance
Luna has been trained and evaluated on a broad range of domains and RAG task-types. Here is how it performs on these evaluation metrics:- For Adherence (Adh) we measure AUROC: Area Under Receiver Operator Characteristic curve. Measures how well the model detects non-adherent responses (hallucinations), balancing the weight of False Negative and False Positive predictions. Range [0-1], higher is better.
- For Relevance (Rel) and Utilization(Util) we measure RMSE: Root Mean Squared Error. Measures model’s Chunk Relevance and Chunk Utilization proximity to ground truth. Range [0-1], lower is better.