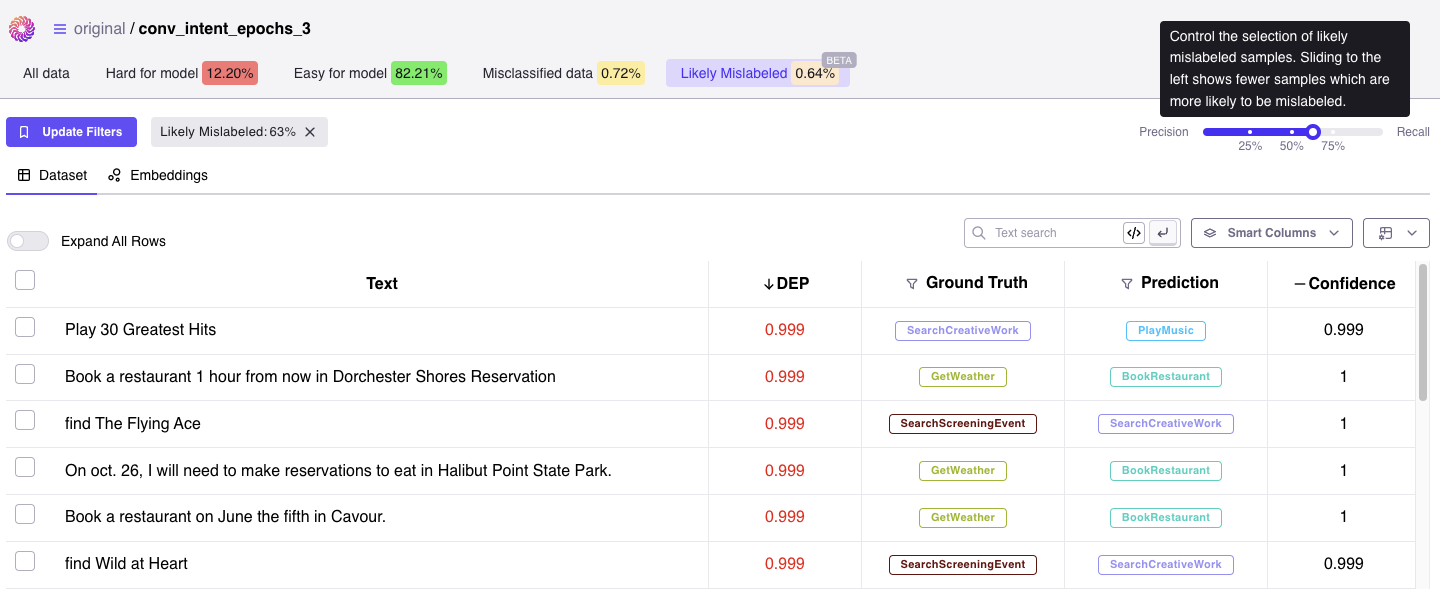
Adjusting the slider for your use-case
The Likely Mislabeled slider allows the user to fine-tune both the qualitative and quantitive output of the algorithm, depending on your use-case.
Setting the threshold for a common use-case: fixed re-labelling budget
Suppose that we have a relabelling budget of only 200 samples. Start with the slider on the Recall side where the algorithm returns all the samples that are likely to be mislabeled. As you move the thumb of the slider towards the Precision side, a hovering box will appear and you should notice the number of samples decreasing, allowing you to fine-tune the algorithm for returning the 200 samples that are most likely to be mislabeled.Likely Mislabeled Computation
Galileo’s Likely Mislabeled Algorithm is adapted from the well known ‘Confident Learning’ algorithm. The working hypothesis of confident learning is that counting and comparing a model’s “confident” predictions to the ground truth can reveal class pairs that are most likely to have class confusion. We then leverage and combine this global information with per-sample level scores, such as DEP (which summarizes individual data sample training dynamics), to identify samples most likely to be mislabeled. This technique particularly shines in multi-class settings with potentially overlapping class definitions, where labelers are more likely to confuse specific scenarios.DEP vs. Likely Mislabeled
Although related, Galileo’s DEP score is distinctly different from the Likely Mislabeled algorithm: samples with a higher DEP score are not necessarily more likely to be mislabeled (even though the opposite is true). While Likely Mislabeled focuses solely on the potential for being mislabeled, DEP more generally measures the potential for “misfit” of an observation to the given model. As described in our documentation, the categorization of “misfit” data samples includes:- Mislabeled samples (annotation mistakes)
- Boundary samples or overlapping classes
- Outlier samples or Anomalies
- Noisy Input
- Misclassified samples
- Other errors
Likely Mislabeled evaluation
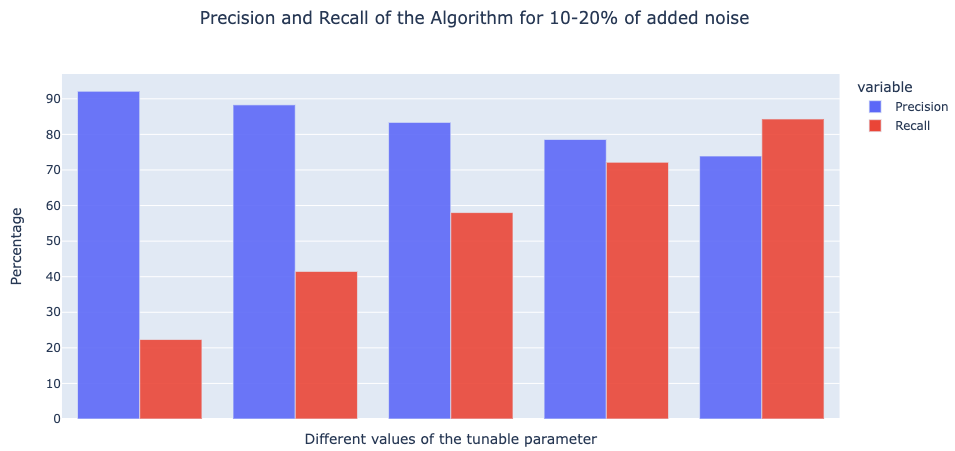
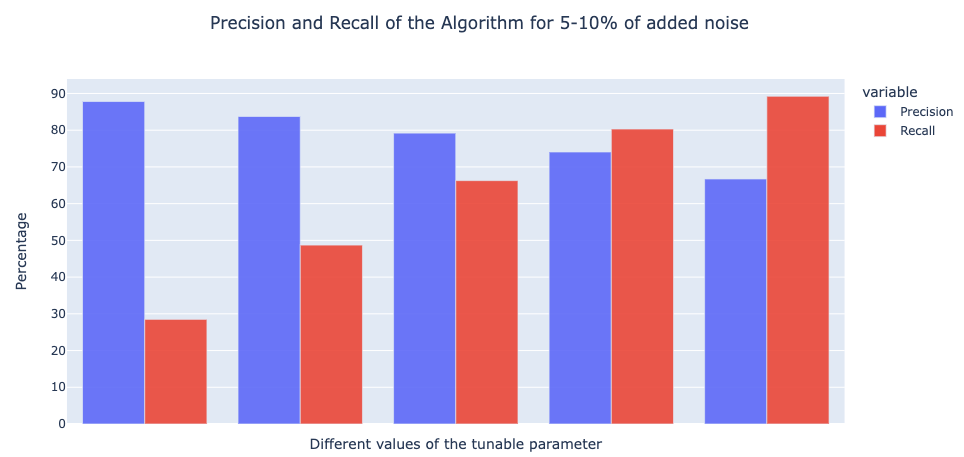
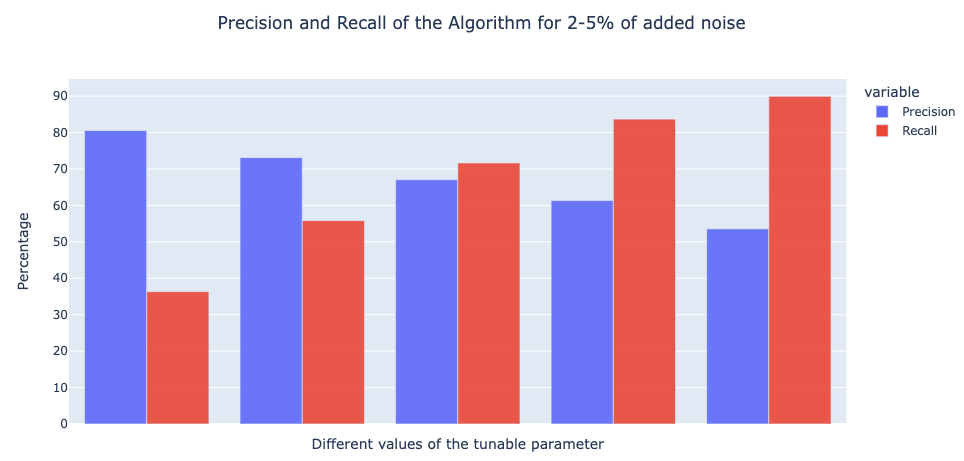
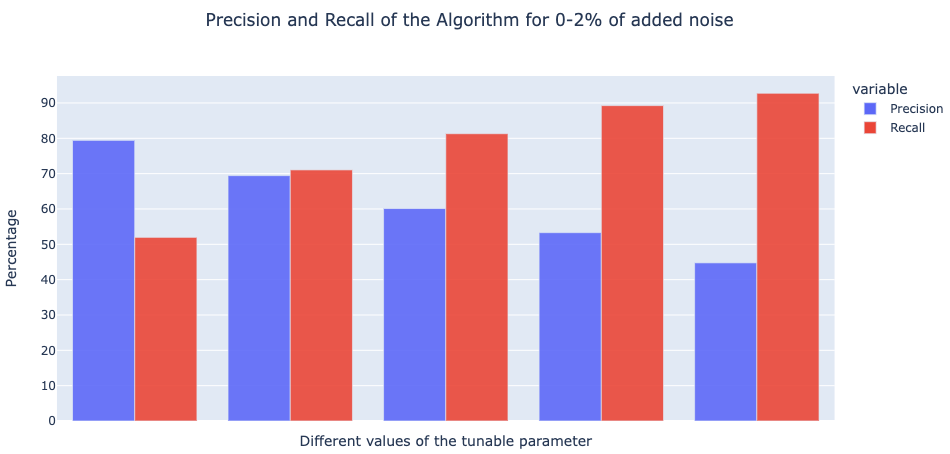
To measure the effectiveness of the Likely Mislabeled algorithm, we performed experiments on 10+ datasets covering various scenarios such as binary/multi-class text classification, balanced/unbalanced distribution of classes, etc. We then added various degrees of noise to these datasets and trained different models on them. Finally, we evaluated the algorithm on how well it is able to identify the noise manually added. Below are plots indicating the Precision and Recall of the algorithm.- 10-20% Noise
- 5-10% Noise
- 2-5% Noise
- 0-2% Noise