Discover the Console
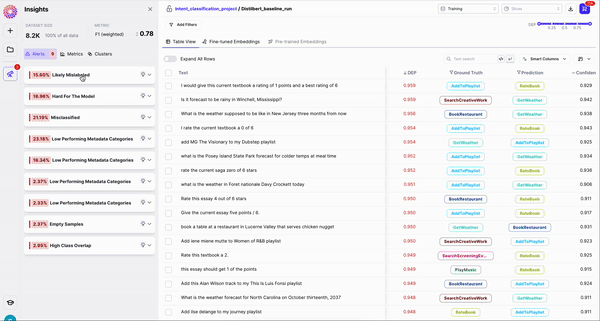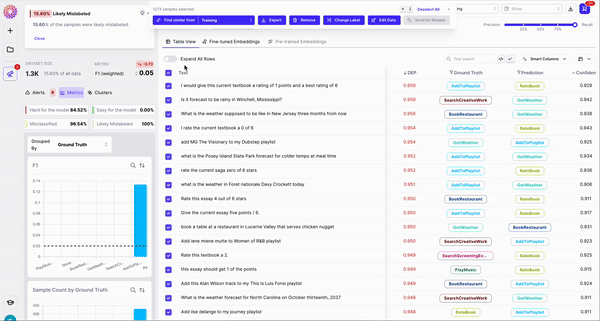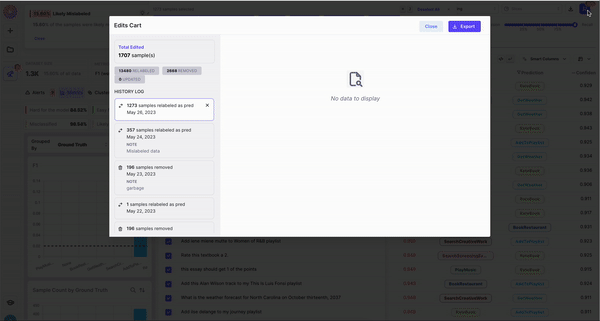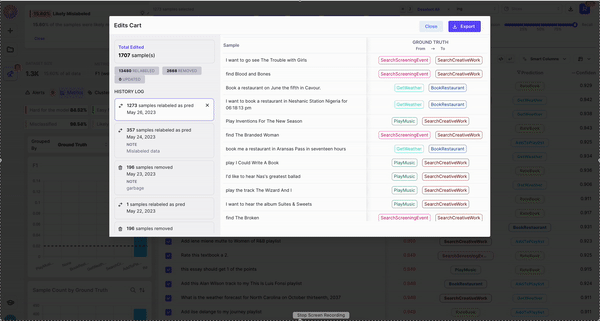
Upon completing a run, you’ll be taken to the Galileo Console. The first thing you’ll notice is your dataset on the right. On each row, we show you the sample’s text, its Ground Truth and Prediction labels, and the Data Error Potential of the sample. By default, your samples are sorted by Data Error Potential.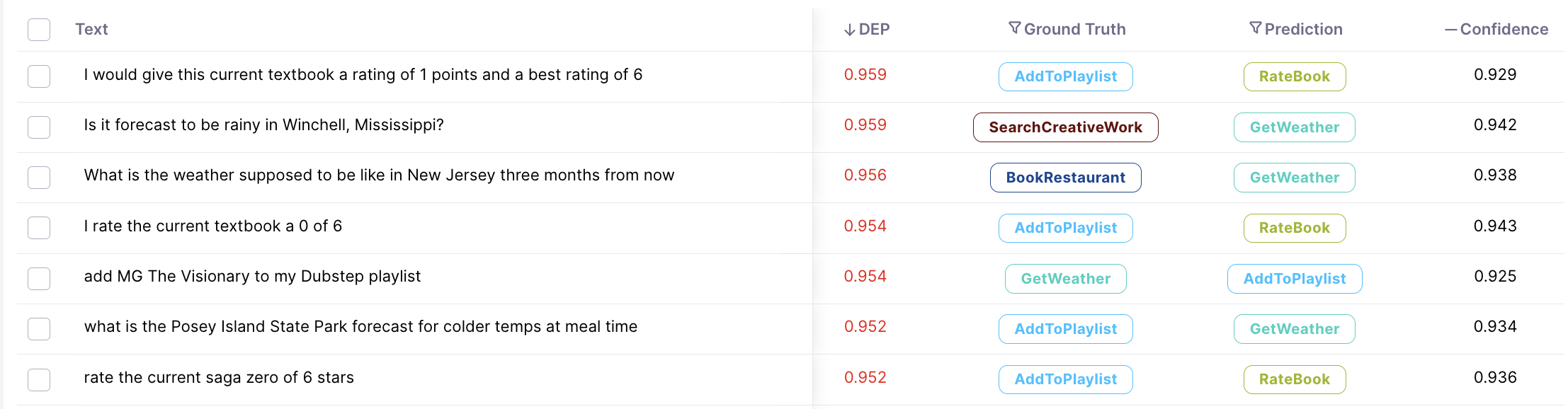
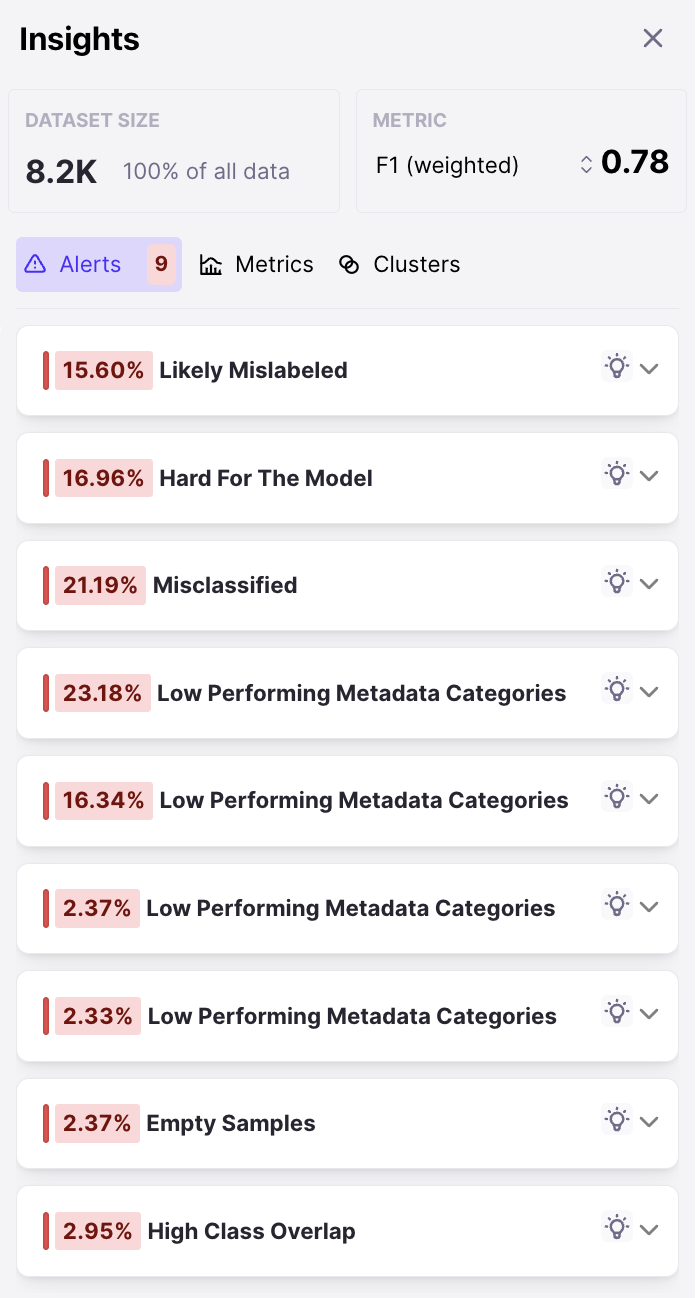
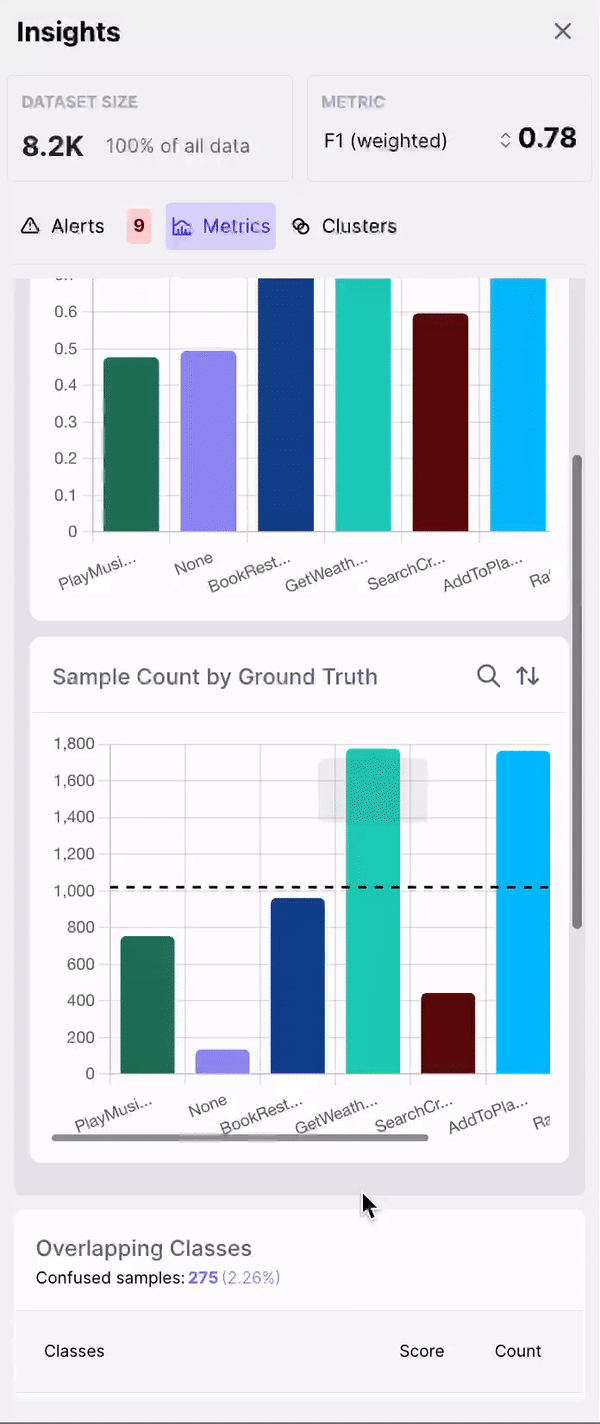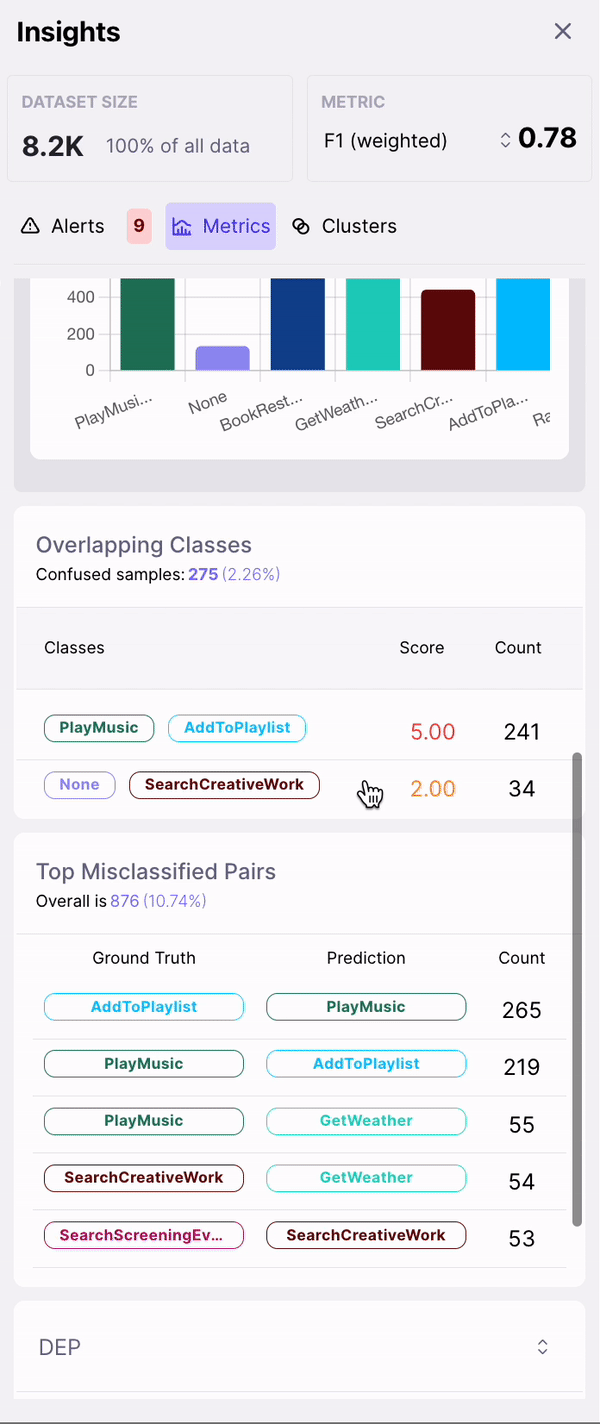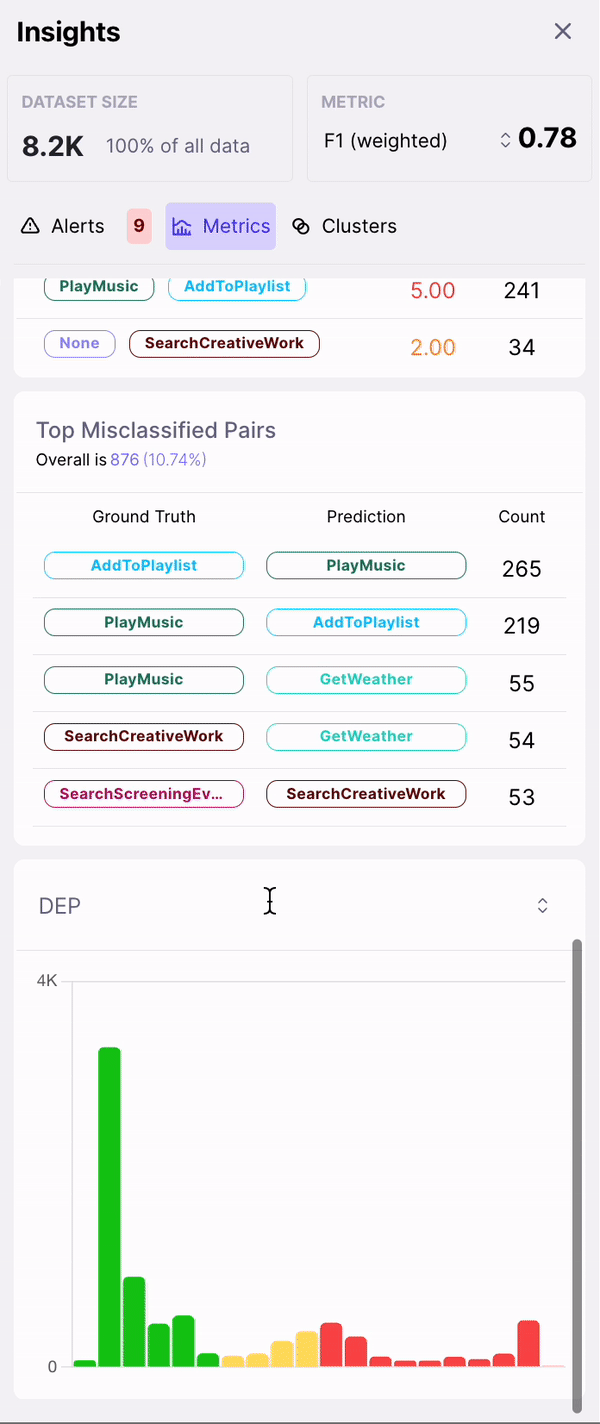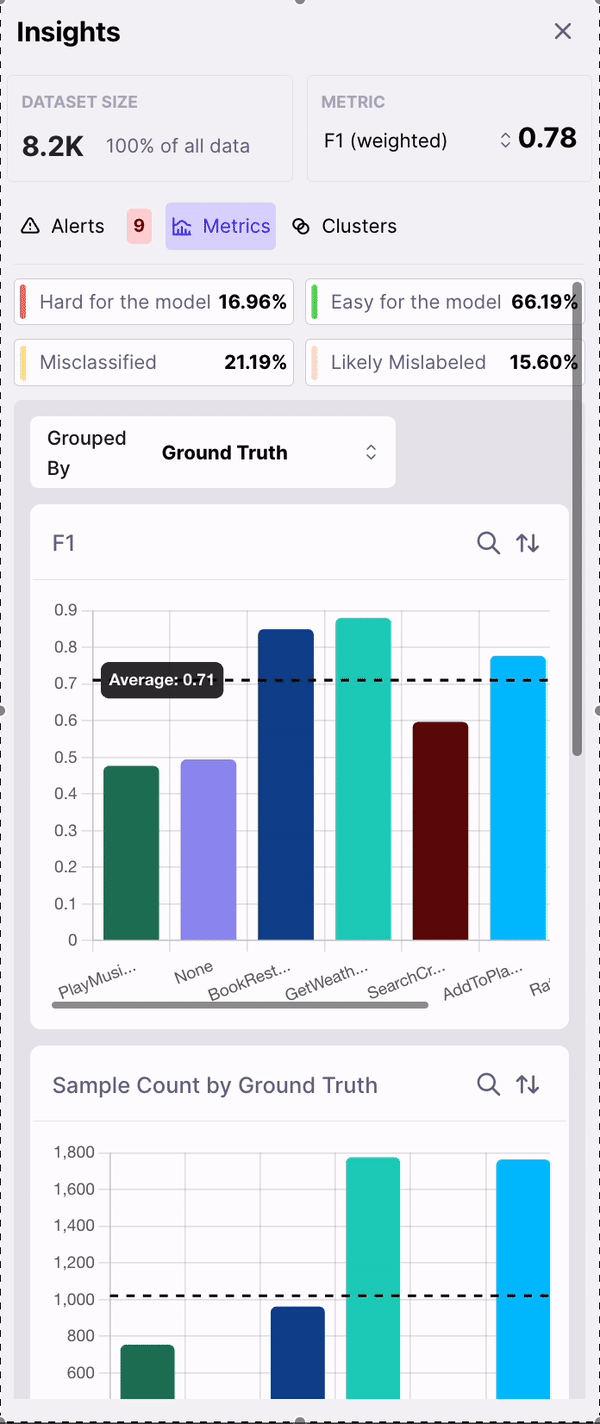
- F1 by Class
- Sample Count by Class
- Overlapping Classes
- Top Misclassified Pairs
- DEP Distribution
- Change Label - Re-assign the label of your image right in-tool
- Remove - Remove problematic images you want to discard from your dataset
- Edit Data - Fix typos or extraneous characters in your samples
- Send to Labelers - Send your samples to your labelers through our Labeling Integrations
- Export - Download your samples so you can fix them elsewhere

Get started with a notebook
Start integrating Galileo with our supported frameworks
- HuggingFace
- PyTorch
- TensorFlow
- Keras