- An Evaluation Set - a list of user queries / inputs that you want to run your evaluation over
- A template / model combination you’d like to try.
Creating a Prompt Run via the Playground UI
- Login to the Galileo console
-
Create a New Project via the ”+” button.
- Give your project a Name, or choose Galileo’s proposed name
- Select “Evaluate”
- Click on Create Project
Choosing a Template, Model, and Tune Hyperparameters
- Choose an LLM, and adjust hyperparameters settings. For custom or self-hosted LLMs, follow the section Setting Up Your Custom LLMs.
- Give your template a name, or select a pre-defined template
-
Enter a Prompt. Put variables in curly braces e.g.
{topic} -
Add Data: There are 2 ways to add data
- Upload a CSV - with the first row representing variable names and each following row representing the values
- Manually add data by clicking on ”+ Add data”
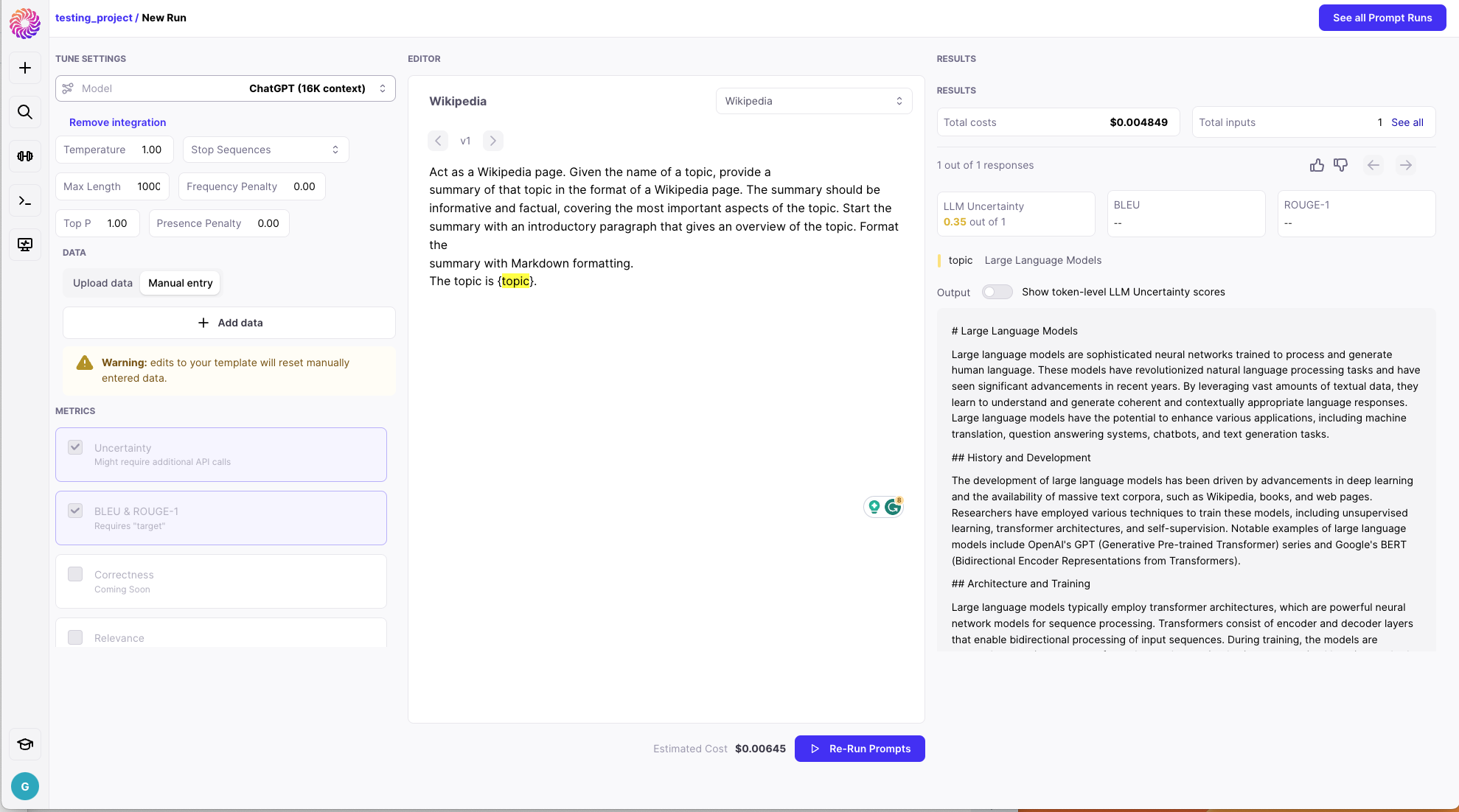
Choosing Your Guardrail Metrics
Galileo offers a comprehensive selection of Guardrail Metrics for monitoring your LLM (Large Language Model) App in production. These metrics are meticulously chosen based on your specific use case, ensuring effective evaluation of your prompts and models. Our Guardrail Metrics encompass:- Industry-Standard Metrics: These include well-known metrics such as BLEU (Bilingual Evaluation Understudy), ROUGE-1 (Recall-Oriented Understudy for Gisting Evaluation), and Perplexity.
- Metrics from Galileo’s ML Research Team: Developed through rigorous research, our team has introduced innovative metrics like Uncertainty, Correctness, and Context Adherence. These metrics are designed to evaluate the reliability and authenticity of the generated content, ensuring it meets high standards of safety, accuracy, and relevance.
Video Walkthrough of how to get started with Galileo Evaluate
The same workflow can also be executed with the Python client, check out Prompt Engineering with Galileo Evaluate here.