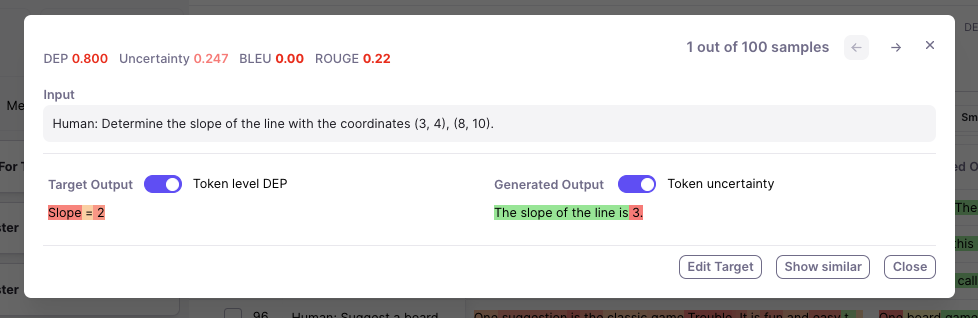
- Low Uncertainty means the model is fairly confident about what to say next, given the preceding tokens
- High Uncertainty means the model is unsure what to say next, given the preceding tokens
On dataset splits where generations are enabled (e.g. the Test split), you’ll be seeing Uncertainty Scores and Token-level Uncertainty highlighting