Getting Started
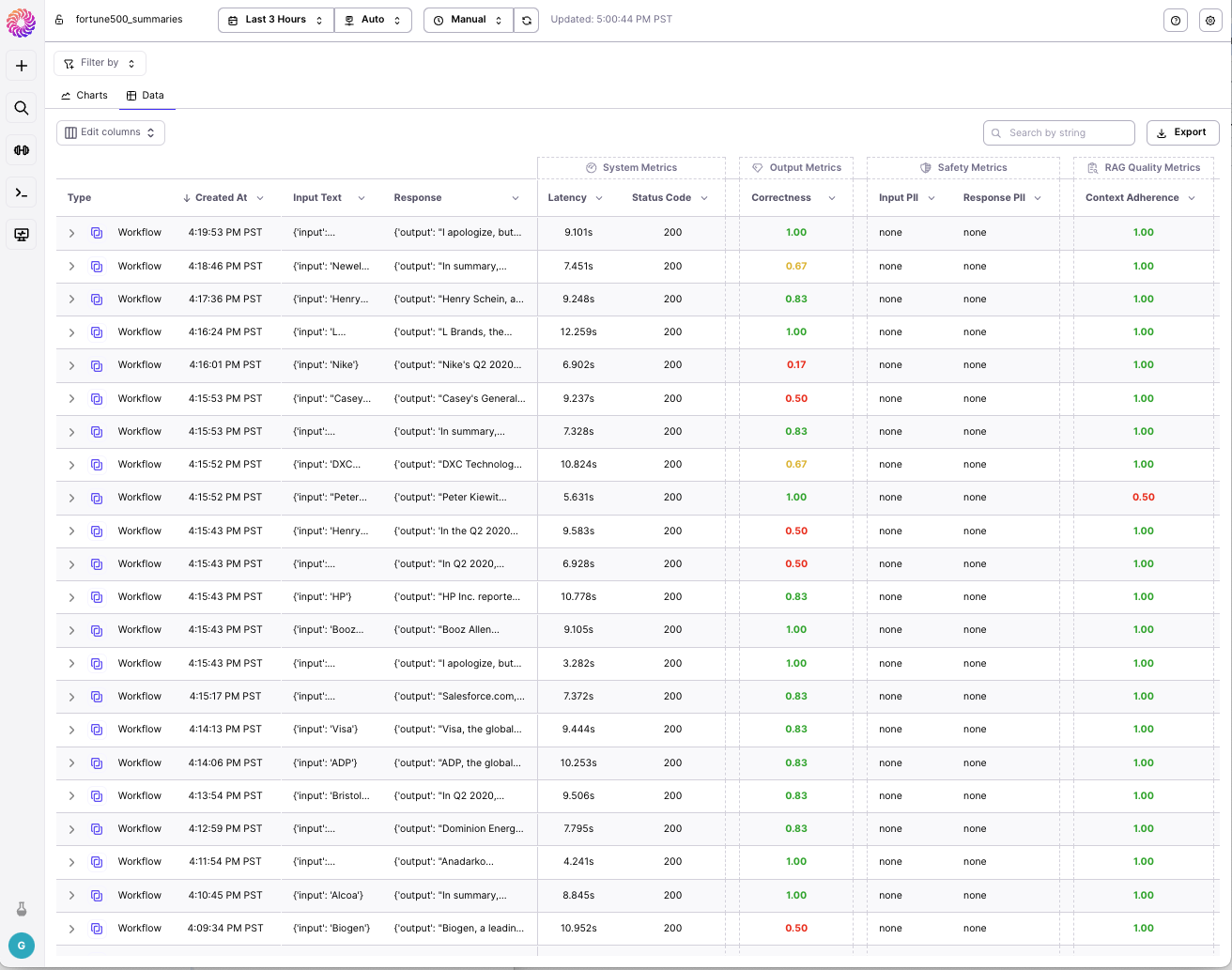
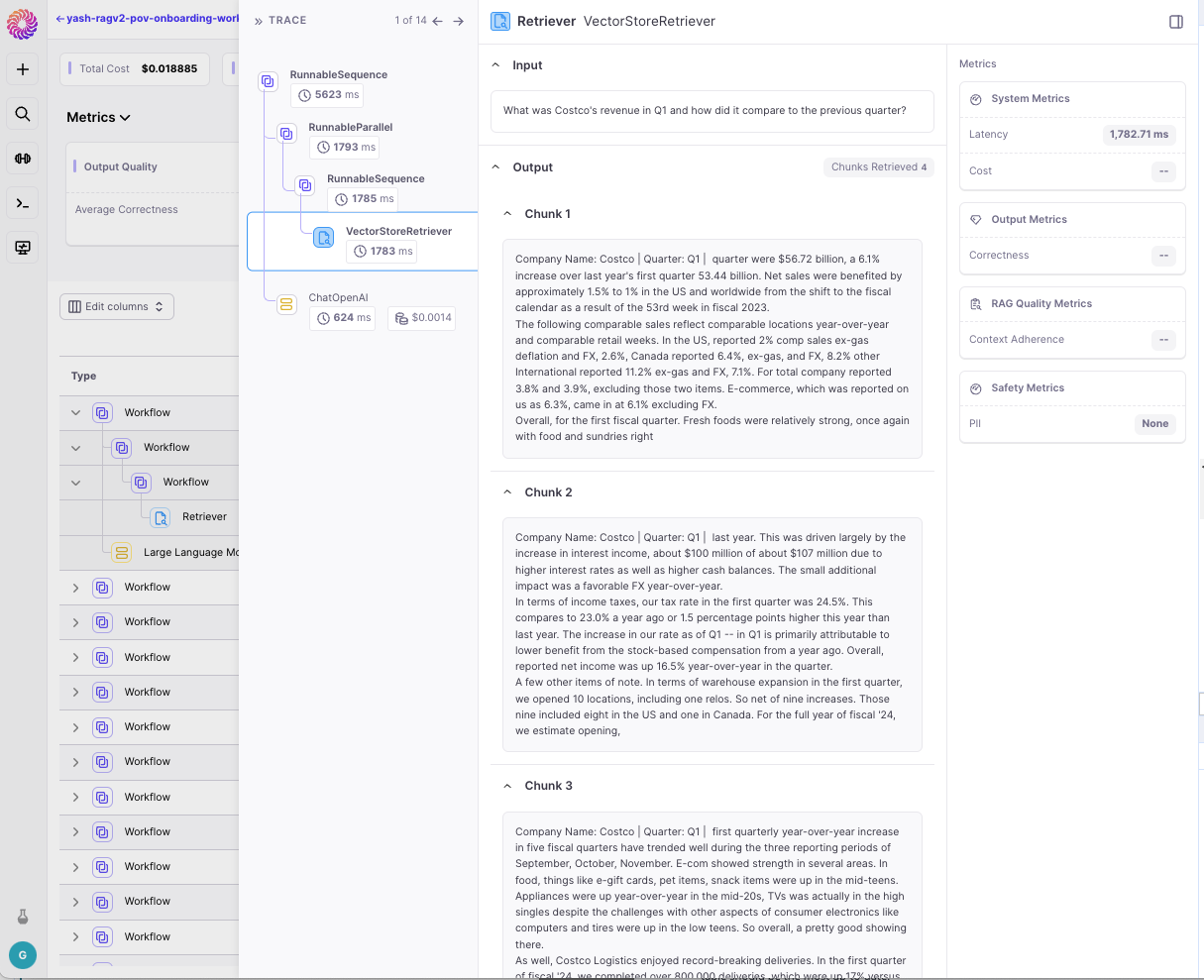
The first step is to integrate Galileo Observe into your application code. If you’re using Langchain, follow the integration instructions here. If you’re not using Langchain, or you’re using a different kind of orchestration service, follow these instructions on how to log your run. For any RAG or multi-step application, make sure to log your retriever node as well as your LLM node.Tracing your Retrieval System
Once you start logging your data to Galileo Observe, you can go to the Galileo Console to analyze your workflow executions. For each execution, you’ll be able to see what the original input and the final output of the workflow were, as well as all the steps that were taken in between.