Getting Started
The first step in evaluating your application is creating an evaluation run. To do this, run your evaluation set (e.g. a set of inputs that mimic the inputs you expect to get from users) through your Agent create a run. Follow our instructions on how to Integrate Evaluate into your existing application.Tracing and Visualizing your Agent
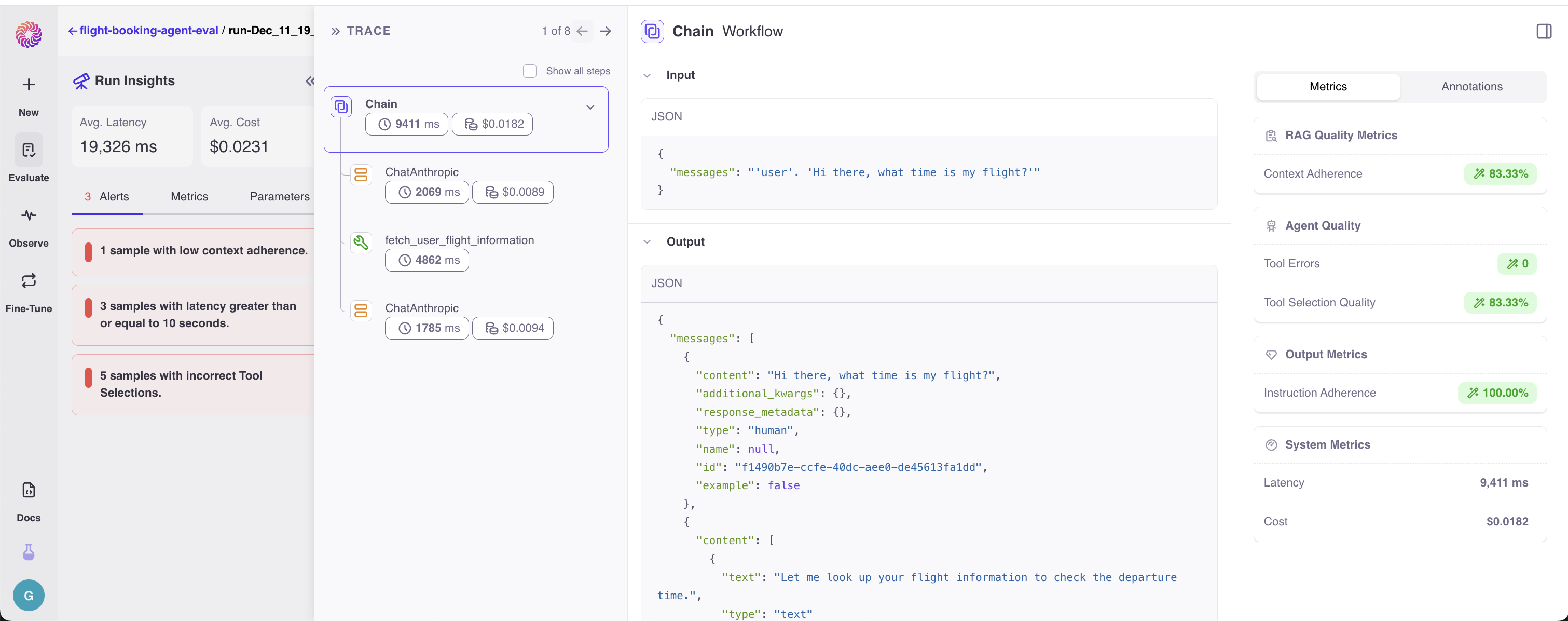
Once you log your evaluation runs, you can go to the Galileo Console to analyze your Agent executions. For each execution, you’ll be able to see what the input into the workflow was and what the final response was, as well as any steps of decisions taken to get to the final result.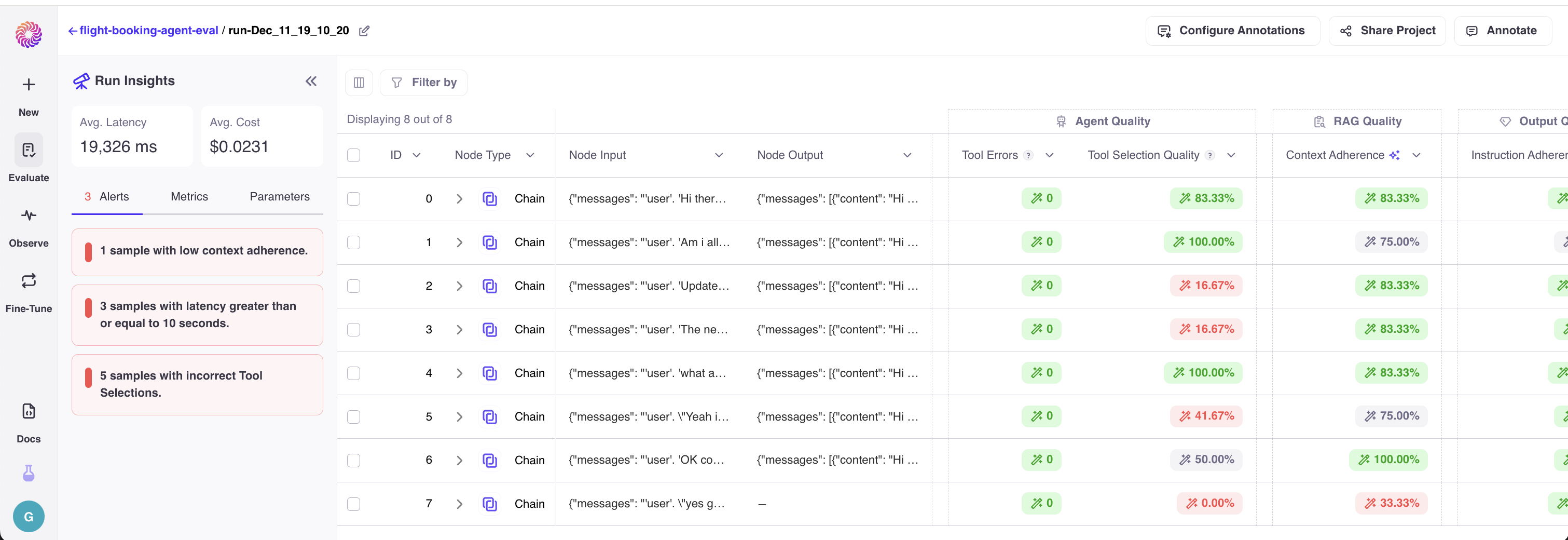
Metrics
Galileo has Galileo Preset Metrics to help you evaluate and debug application. In addition, Galileo supports user-defined custom metrics. When logging your evaluation run, make sure to include the metrics you want computed for your run. More information on how to evaluate and debug them on the console. For Agents, the metrics we recommend to use are:- Action Completion: A metric at the session level detecting whether the agent successfully accomplished all user’s goals. This metric will show use-cases where the Agent is not able to fully help the user in all of its tasks.
- Action Advancement: A metric at the workflow level detecting whether the agent successfully accomplished or advanced towards at least one user goal. This metric will show use-cases where the Agent is not able to help the user in any of its tasks.
- Tool Selection Quality: A metric on your LLM steps that detects whether the correct Tool and Parameters were chosen by the LLM. When you use LLMs to determine the sequence of steps that happen in your Agent, this metric will help you find ‘planning’ errors in your Agent.
- Tool Errors: A metric on your Tool steps that detects whether they executed correctly. Tools are a common building block for Agents. Detecting errors and patterns in those errors is an important step in your debugging journey.
- Instruction Adherence: A metric on your LLM steps that measures whether the LLM followed its instructions.
- Context Adherence: If your Agent uses a Retriever or has summarization steps, this metric can help detect hallucinations or ungrounded facts in the response.