input, output, and metadata.
The input column is what you can reference inside a prompt template to craft your prompt.
The output column can be used to store reference outputs or ground truth outputs.
The metadata column can be used to store any properties useful to group and filter the rows in the dataset.
Using Datasets in the Galileo Console
Create a dataset
From the Datasets page, click the “Create Dataset” button.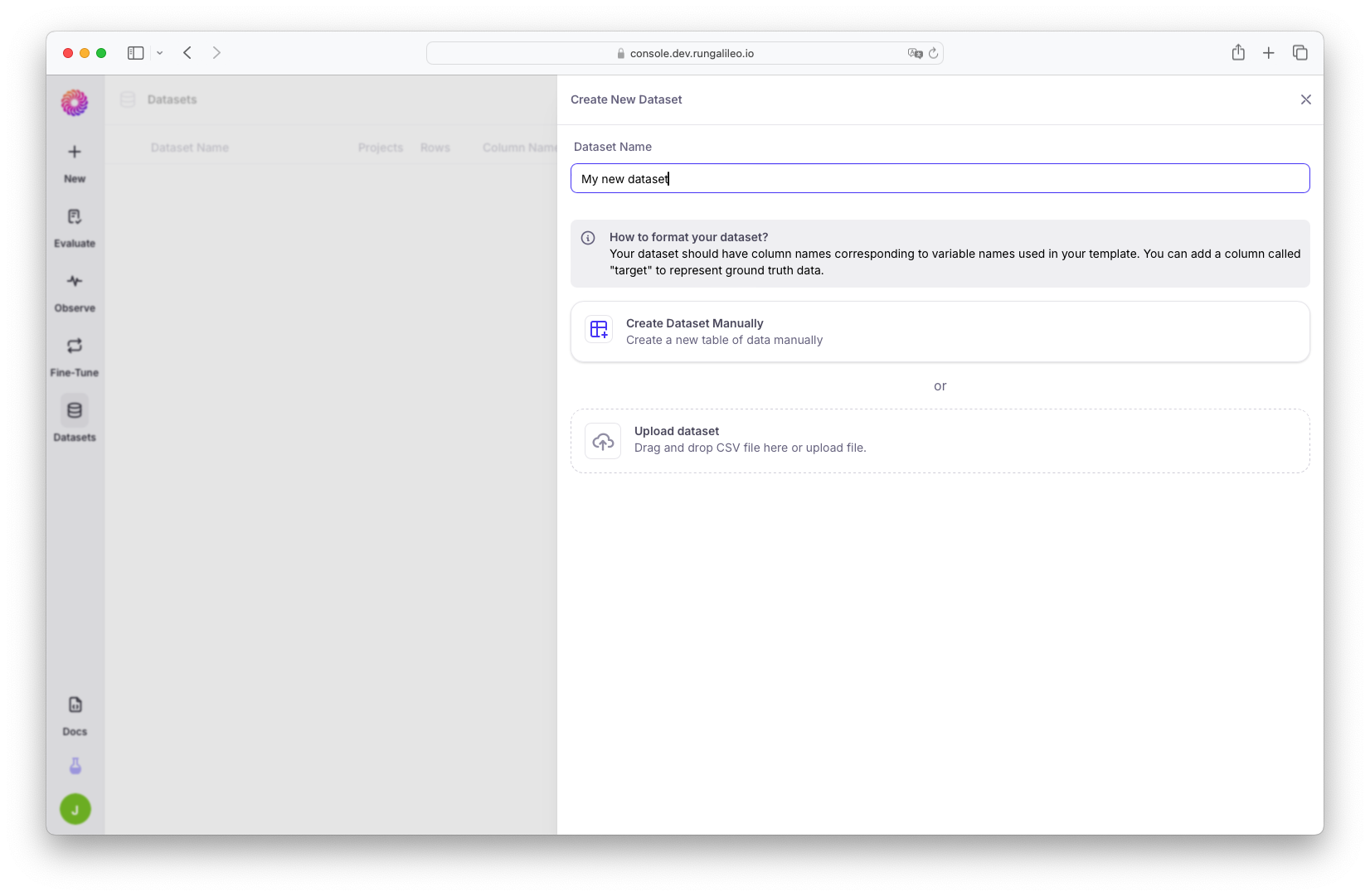
Using a dataset in an evaluation run
When creating a new evaluation run, you can select a dataset to use as input.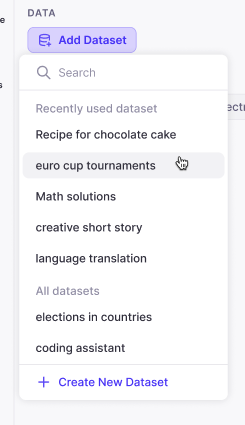
Using Datasets in code
Prerequisites
For Python, install thepromptquality library.
For TypeScript, install the @rungalileo/galileo package.
Create a dataset
You can create a new dataset by running:- A dictionary mapping column names to lists of values (as shown above).
-
A list of dictionaries, where each dictionary represents a row in the dataset, e.g.
-
A path to a file in either CSV, Feather, or JSONL format, e.g.