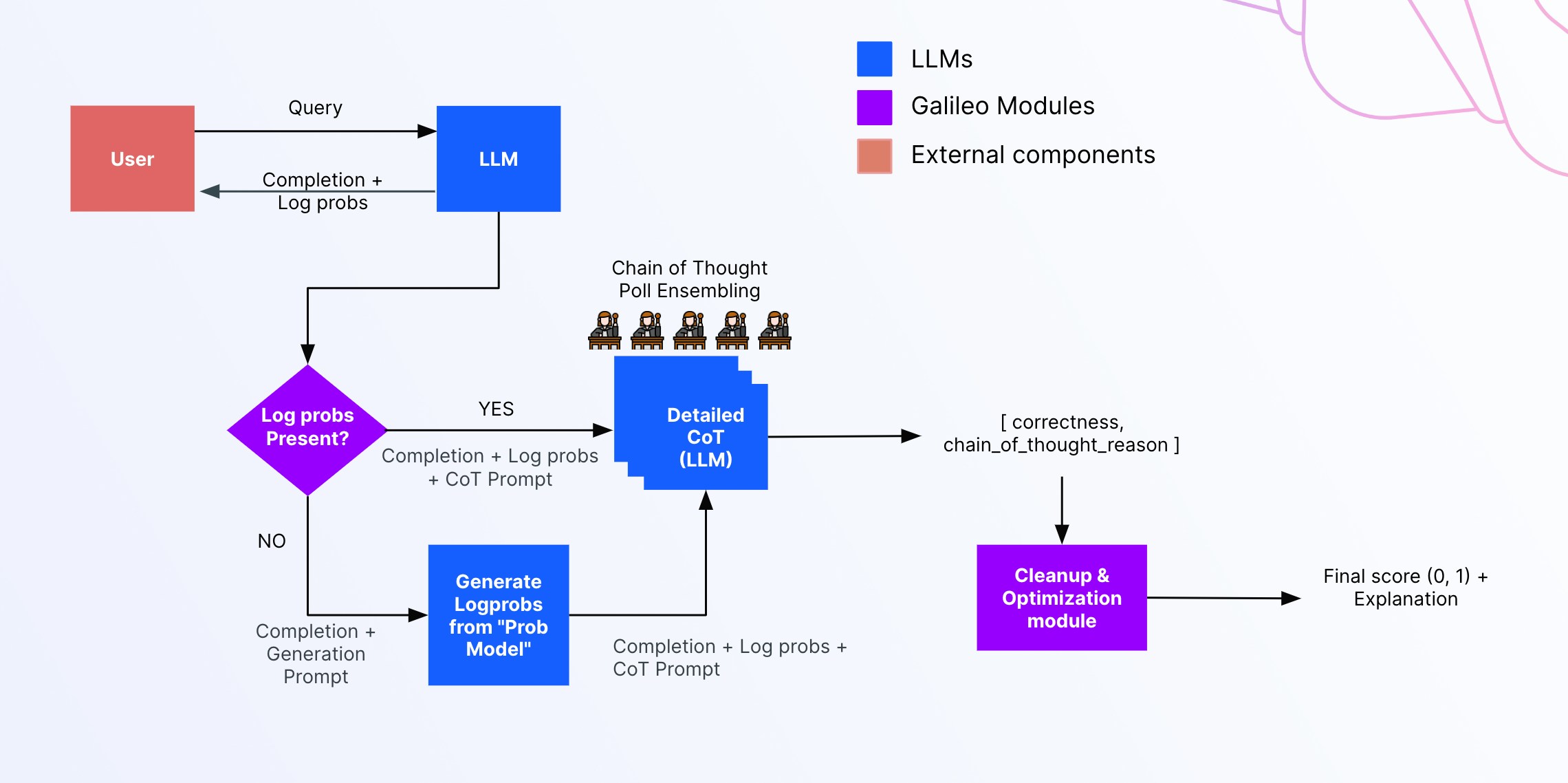
Guardrail Metrics
Galileo’s Guardrail Metrics are built to help you shed light on where and why the model produces an undesirable output.Uncertainty
Uncertainty measures the model’s certainty in its generated tokens. Because uncertainty works at the token level, it can be a great way of identifying where in the response the model started hallucinating. When prompted for citations of papers on the phenomenon of “Human & AI collaboration”, OpenAI’s ChatGPT responds with this:
Context Adherence
Context Adherence measures whether your model’s response was purely based on the context provided, i.e. the response didn’t state any facts not contained in the context provided. For RAG users, Context Adherence is a measurement of hallucinations. If a response is grounded in the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is not grounded (i.e. it has a value of 0 or close to 0), it’s likely to contain facts not included in the context provided to the model.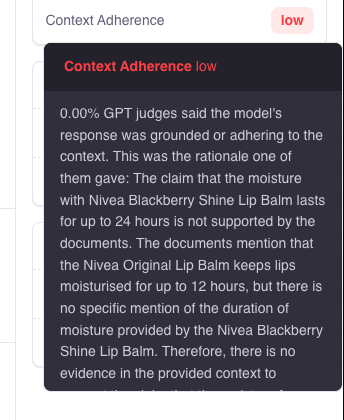
Correctness
Correctness measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls. If the response is factually consistent (value close to 1), the information is likely be correct. We use our proprietary ChainPoll Technique (Research Paper Link) using a combination of Chain-of-Thought prompting and Ensembling techniques to provide the user with a 0-1 score and an explanation to the Hallucination. The explanation why something was deemed incorrect or not can be seen upon hovering over the metric value.NoteBecause correctness relies on external Large Language Models and their knowledge base, its results are only as good as those models’ knowledge base.