Getting Started
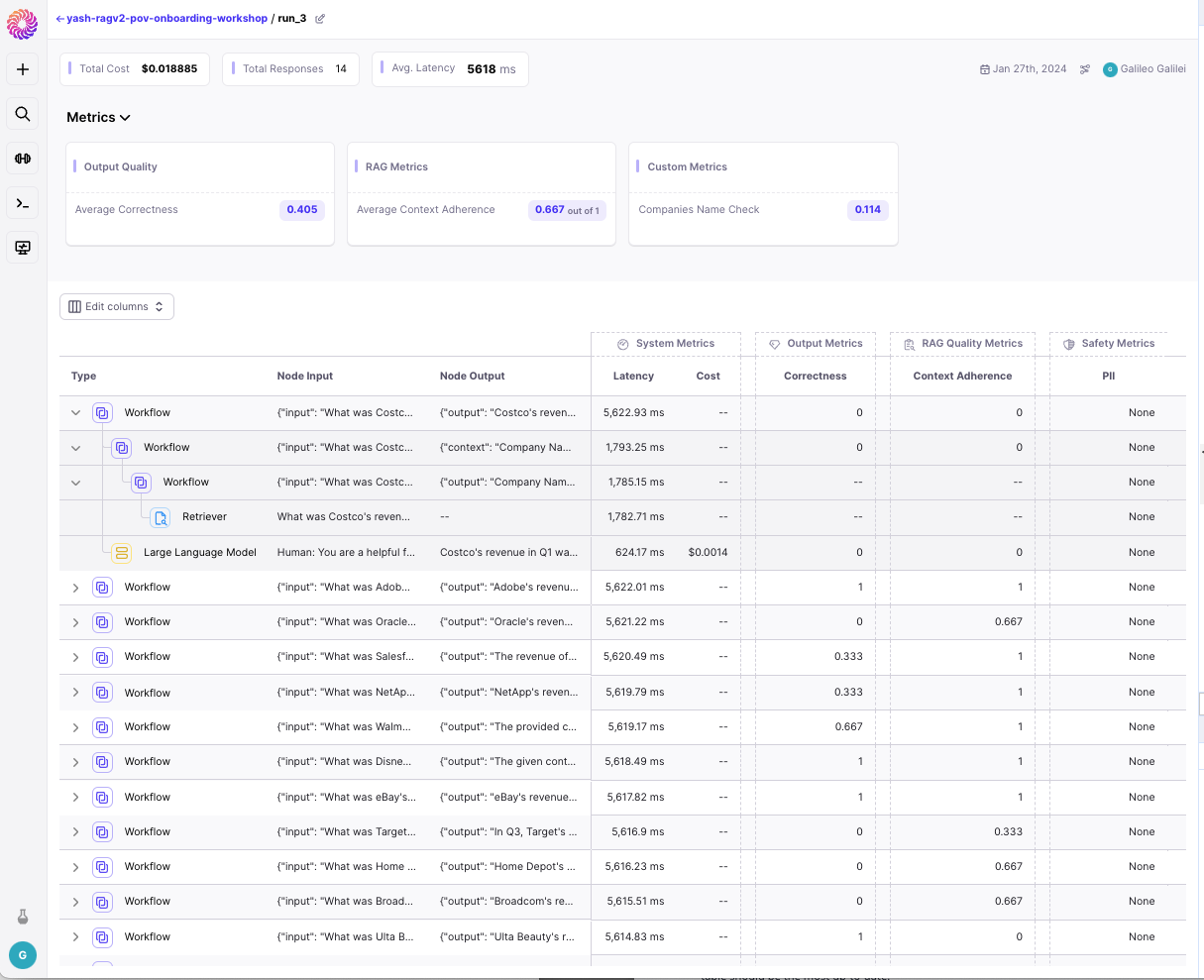
The first step in evaluating your application is creating an evaluation run. To do this, run your evaluation set (e.g. a set of inputs that mimic the inputs you expect to get from users) through your RAG system and create a prompt run. Follow these instructions to integratepromptquality into your RAG workflows and create Evaluation Runs on Galileo.
If you’re using LangChain, we recommend you use the Galileo Langchain callback instead. See these instructions for more details.
Keeping track of what changed in your experiment
As you start experimenting, you’re going to want to keep track of what you’re attempting with each experiment. To do so, use Prompt Tags. Prompt Tags are tags you can add to the run (e.g. “embedding_model” = “voyage-2”, “embedding_model” = “text-embedding-ada-002”). Prompt Tags will help you remember what you tried with each experiment. Read more about how to add Prompt Tags here.Tracing your Retrieval System
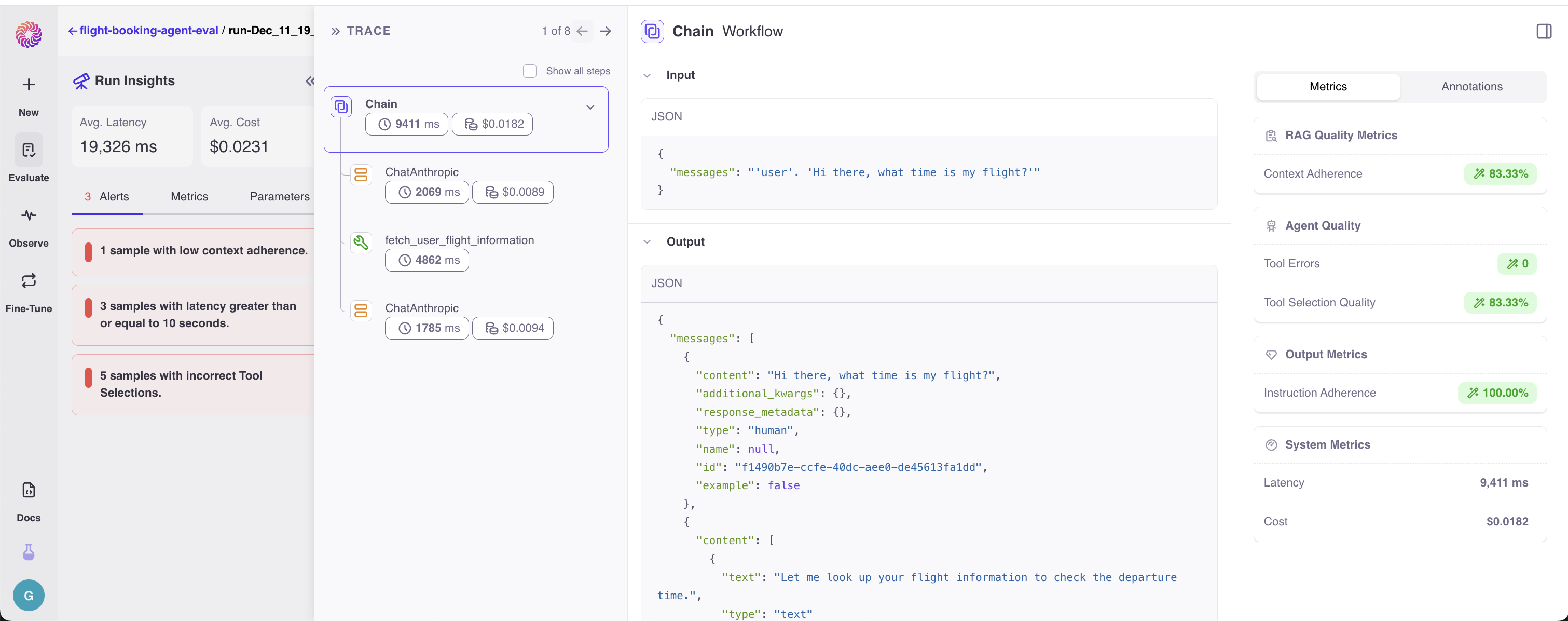
Once you log your evaluation runs, you can go to the Galileo Console to analyze your workflow executions. For each execution, you’ll be able to see what the input into the workflow was and what the final response was, as well as any intermediate results.