Adding tags with promptquality
A tag has three key components:
- key: the name of your tag i.e model name
- value: the value in your run i.e. gpt-4
- tag_type: the type of the tag. Currently tags can be RAG or GENERIC
Logging Workflows
If you are using a workflow, you can add tags to your workflow by adding the tag to the EvaluateRun object.Prompt Run
We can add tags to a simple Prompt run. For info on creating Prompt runs, see Getting StartedPrompt Sweep
We can also add tags across a Prompt sweep, with multiple templates and/or models. For info on creating Prompt sweeps, see Prompt SweepsLangChain Callback
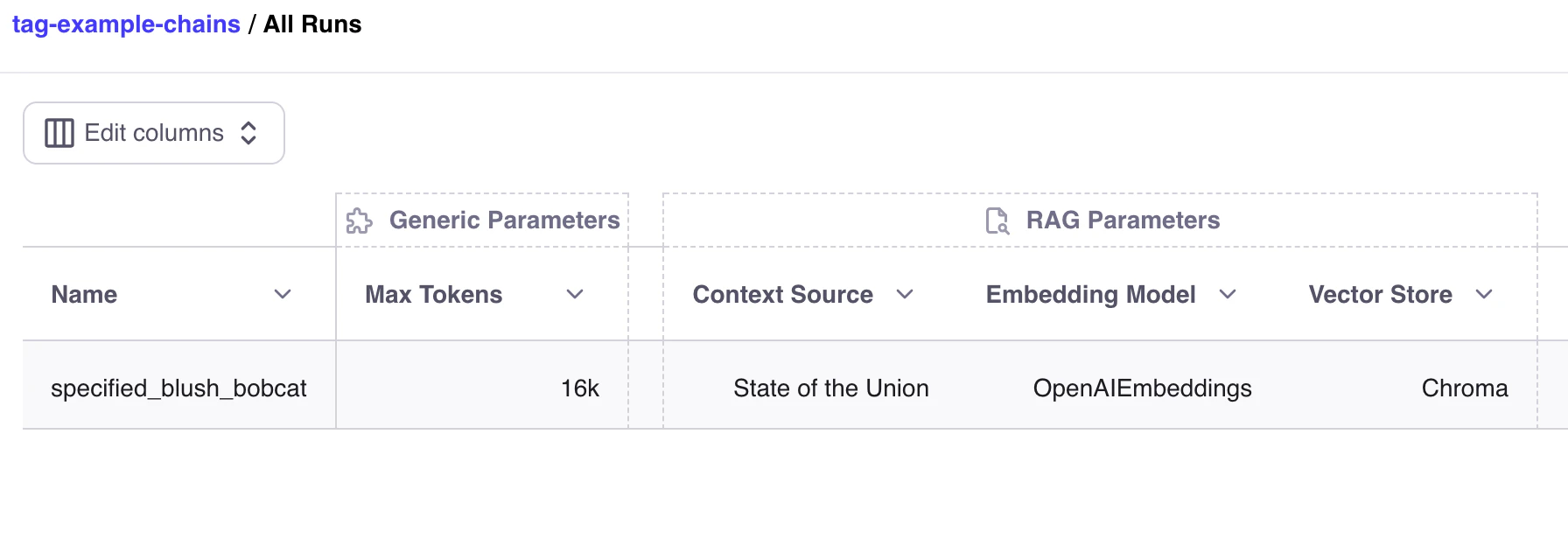
We can even add tags, through the GalileoPromptCallback, to more complex chain runs, with LangChain. For info on using Prompt with chains, see Using Prompt with Chains or multi-step workflowsViewing Tags in the Galileo Evaluation UI
You can then view your tags in the Galileo Evaluation UI: